Anemic Domain Models
- Anemic Domain Models In A Nutshell
- The Problems With Anemic Domain Models
- "Service-juggling"
- Mixing Responsibilities: Application Logic and Business Logic
- Inconsistent Domain State
- SRP Challenges: Violating the Single-Responsibility Principle
- Going Against Object-Oriented Programming (OOP)
- Rich Domain Models: A Better Alternative
- Why Anemic Domain Models Persist
- 1. Anemic Domain Models are the Path of least Resistance
- 2. Layered Architecture Encourages Anemic Domain Models
- 3. Architecture Tends Not to Evolve
- 4. Lack of Awareness
- From Simplicity to Elegance
It was not long ago I championed anemic models. They were great! Easy to set up for testing and easy to work with. They were malleable and adapted to whatever context I needed.
I was wrong - and as a result, I've created a lot of code that I'm no longer proud of. I had never learned that there was an alternative to anemic domain models, and my experience was only with anemic models.
In this post, I aim to do three things:
- Explain why I believe anemic domain models are an issue.
- Explore the alternative.
- Discuss why I believe anemic domain models continue to be used.
Anemic Domain Models In A Nutshell
Every codebase has some core concepts. A banking system might have the concept of "accounts", a healthcare system might have the concept of "patients", and applications for car rental services might have the concept of "car". We call these "Domain models" - key concepts within our applications that most of the logic operates on. They're often represented as an entity used in a database of sorts.
Let's use "Account" as an example and look at what an anemic implementation might look like in Java:
import javax.persistence.*;
@Entity
@Table(name = "accounts")
public class Account {
@Id
@Column(name = "account_number", unique = true, nullable = false)
private String accountNumber;
@Column(name = "balance", nullable = false)
private double balance;
public Account() {
}
public Account(String accountNumber, double balance) {
this.accountNumber = accountNumber;
this.balance = balance;
}
public String getAccountNumber() {
return accountNumber;
}
public void setAccountNumber(String accountNumber) {
this.accountNumber = accountNumber;
}
public double getBalance() {
return balance;
}
public void setBalance(double balance) {
this.balance = balance;
}
}If your code looks like the above, then this post is for you!
This is an anemic domain model: A core concept of an application that contains no actual logic.
The Problems With Anemic Domain Models
In the previous section, we introduced anemic domain models and explored a basic example of an account domain model. Let's uncover the inherent problems with anemic domain models that lead to code complexity and maintainability challenges.
"Service-juggling"
In this example, we're will assume that layered architecture is used - though the same problem will manifest regardless of when we have a codebase with anemic domain models exist.
We usually have at least three layers in a layered architecture (or N-tier architecture). In this case, we're using it for a backend system, so we have our modules set up like this:
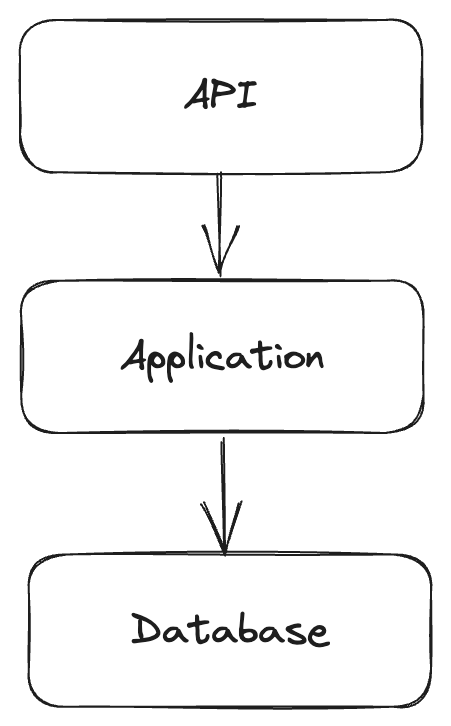
Layered architecture is pretty common, but to quickly summarise:
- "API" is where external calls enter. Assume something like a regular REST API.
- "Application" is where all business logic happens.
- "Database" is where you find your DAOs and repositories - whatever persists your data.
Let's assume we're making a banking application and will implement support for transactions. It is fair to assume that we're going to end up with a TransactionService at some point:
public class TransactionService {
private final TransactionDao transactionDao;
public TransactionService(TransactionDao transactionDao) {
this.transactionDao = transactionDao;
}
@Transactional
public void create(double amount, String vendor) {
var transaction = new Transaction(amount, vendor);
transactionDao.save(transaction);
}
}Looks harmless enough, right? But simply creating a new transaction isn't enough. We also need to update the account balance on the Account object. How can we do that? One way would be to create an AccountService, which does that for us. Our TransactionDao will now look something like this:
public class TransactionService {
private final TransactionDao transactionDao;
private final AccountService accountService;
public TransactionService(
TransactionDao transactionDao,
AccountService accountService) {
this.transactionDao = transactionDao;
this.accountService = accountService;
}
@Transactional
public void create(double amount, String vendor, String accountNumber) {
var transaction = new Transaction(amount, vendor, accountNumber);
accountService.updateAccountBalance(amount, accountNumber);
transactionDao.save(transaction);
}
}The code is still fairly easy to manage, but we just added some extra complexity. The updateAccountBalance method probably does some database operations of its own, but we can't be entirely sure unless we look into it.
We also had to add a dependency to the AccountService itself which will become an issue later.
Let's complicate things further by adding that this application deals with credit cards where purchases may produce bonus points. The points are not fixed. You might get a certain percentage of points if you shop at a specific store or date (or both). You might get a certain percentage buying a specific brand of cereal. Etc. There are no real boundaries of how such a bonus can be configured, and we don't need to worry about it for our example. All we need to worry about is that any transaction may generate some bonus - which means we need a BonusService:
public class TransactionService {
private final TransactionDao transactionDao;
private final AccountService accountService;
private final BonusService bonusService;
public TransactionService(
TransactionDao transactionDao,
AccountService accountService,
BonusService bonusService) {
this.transactionDao = transactionDao;
this.accountService = accountService;
this.bonusService = bonusService;
}
@Transactional
public void create(double amount, String vendor, String accountNumber) {
var transaction = new Transaction(amount, vendor, accountNumber);
accountService.updateAccountBalance(amount, accountNumber);
bonusService.generate(transaction);
transactionDao.save(transaction);
}
}Now we're starting to see some of the issues with anemic models. Now the TransactionService already has dependencies, which isn't that much. However, it is fair to assume that it will continue to grow since the concept of a "Transaction" is so important.
Earlier, I did elude to the fact that it is near infinite ways one could configure how bonuses are generated. It is, therefore, fair to assume that BonusService uses other services to complete its job - and possibly multiple database calls.
We will come back to AccountService as it contains other issues, but now let's focus on the dependencies.
At some point, we want to convert these bonus points into money that goes into the customer account. This is the company's business model, so we need to add support for that. How can we do that?
I don't think this logic really belongs in TransactionService. There will be a transaction at some point, but it doesn't derive from Transaction. The main logic should exist within BonusService - so let's do that!
But we can't... Let's look at the classes and their dependencies again:
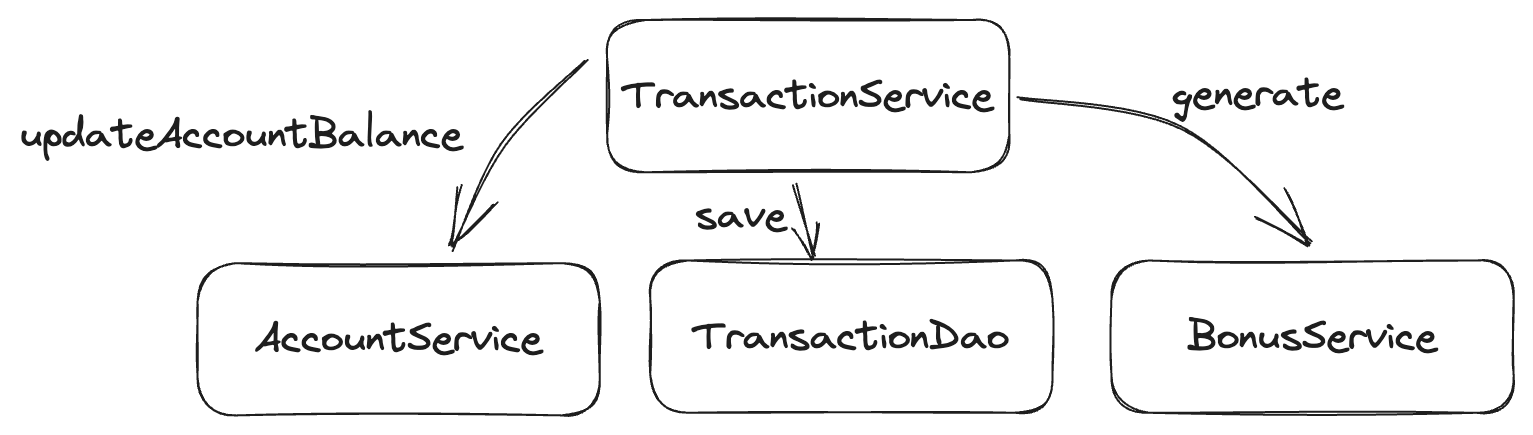
What would happen if we were to implement this within BonusService? We'd end up with something like this:
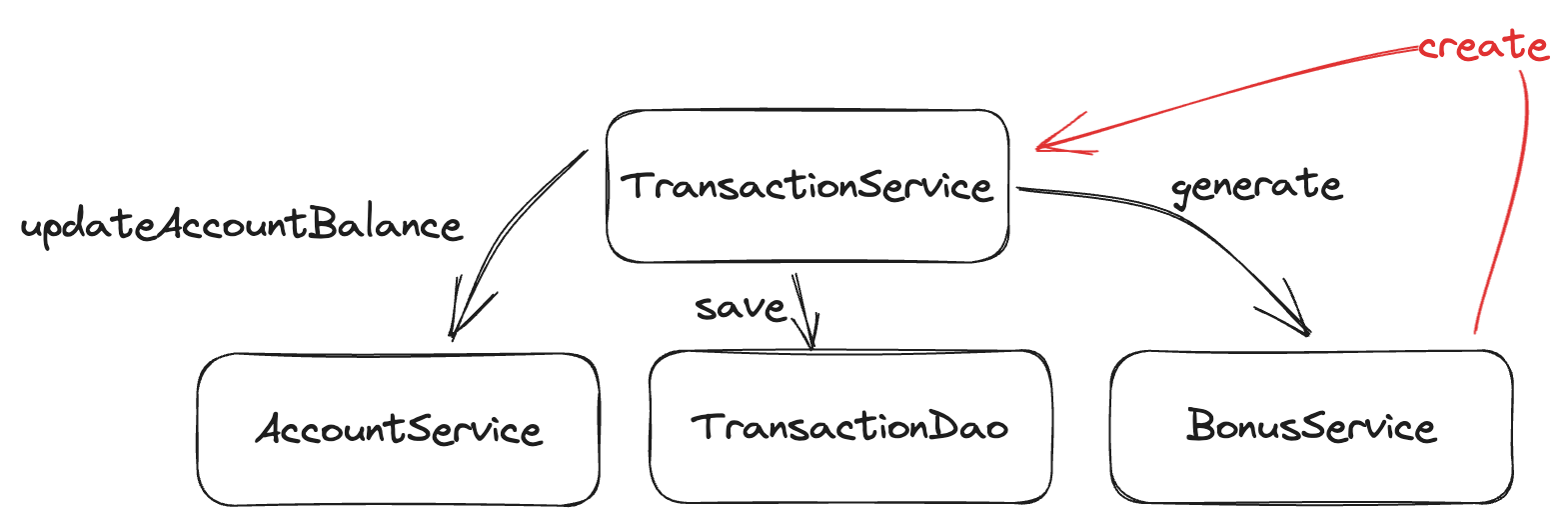
In other words: We just made recursive dependencies - which is a bad thing for multiple reasons (but in our case, it means we can't use constructor-based dependency injection).
How can this be solved? One common way would be either to force the logic into TransactionService, or to create a new BonusSettlementService, and we end up with something like this:
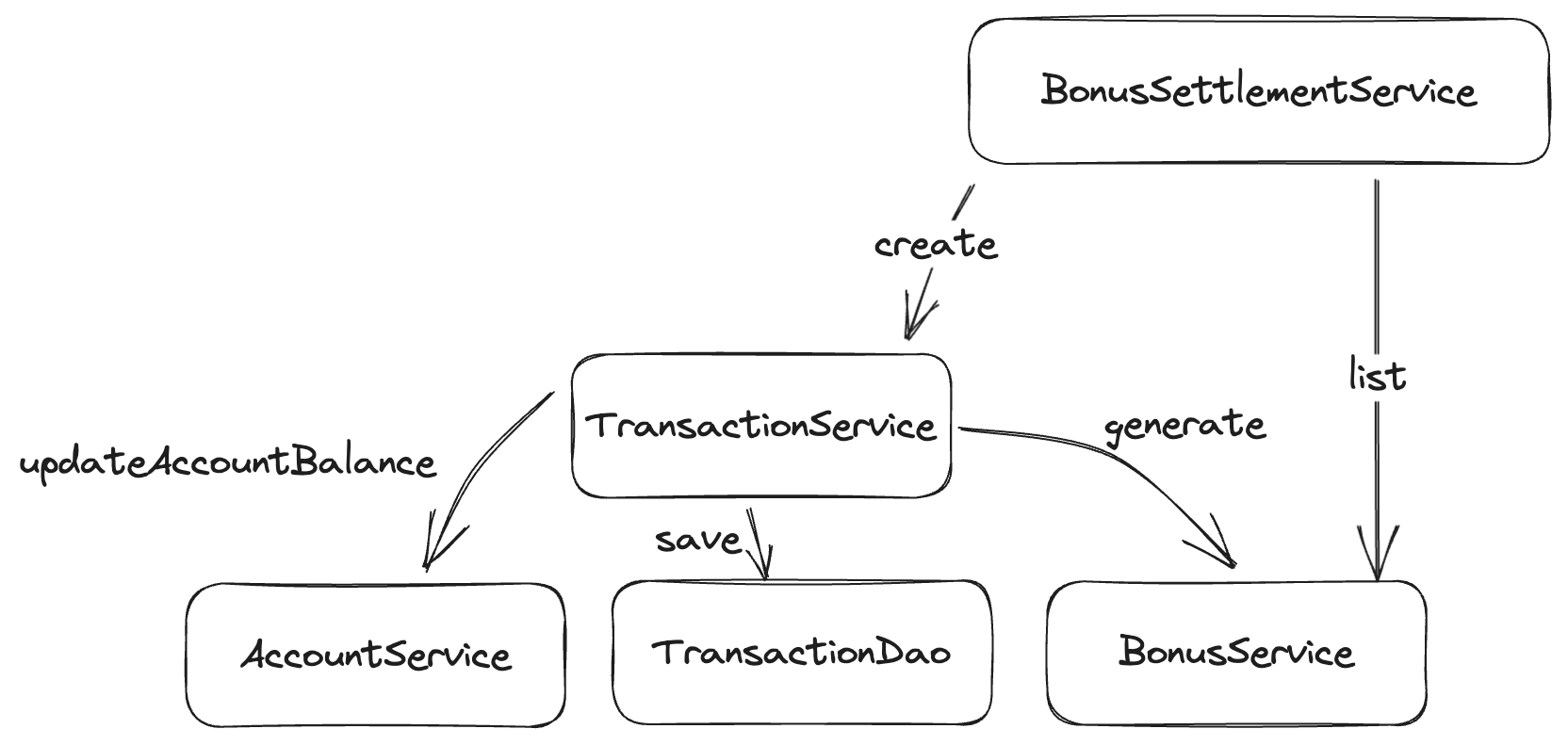
Some might argue that this is just logical - I disagree. We had to invent a new class simply because our object hierarchy became complex. So far, we've followed a pretty clear pattern: If there's an entity, then the entity gets its own service. Our application has no "BonusSettlement" entity; thus, it breaks that design (Not that it was a good design).
I've myself thought of this as architecture. I've done this and thought "Hey, John! Great work!". It isn't. What we're observing is a developer trying to work around the restrictions posed by the architecture.
Splitting functionality into other classes should be strategic - not forced. We do it because we see it improving the design, not because we have no other options. The lack of options indicates that the architecture can't handle the complexity we need. The end result is the juggling of services - we must invent new services or force functionality where they don't belong so that the compiler/runtime doesn't yell at us.
Mixing Responsibilities: Application Logic and Business Logic
Let's go back to the TransactionService for a second:
public class TransactionService {
//Code...
@Transactional
public void create(double amount, String vendor, String accountNumber) {
var transaction = new Transaction(amount, vendor, accountNumber);
accountService.updateAccountBalance(amount, accountNumber);
bonusService.generate(transaction);
transactionDao.save(transaction);
}
}What kind of logic do you see here? Most might answer "business logic", but that's not entirely true.
These three lines probably fall under the term "business logic":
var transaction = new Transaction(amount, vendor, accountNumber);
accountService.updateAccountBalance(amount, accountNumber);
bonusService.generate(transaction);But is this business logic?
transactionDao.save(transaction);I would argue not. This is application logic - stuff that needs to happen for the application to make sense. Business logic expresses the actual rules of the business. I.e., when a transaction must be created, the account balance must be updated, and bonus must be generated. The fact that it needs to be persisted is application logic - same with fetching data from the database.
Within updateAccountBalance it is fair to assume that we fetch an account at some point - not because any business logic dictates that we must fetch it from a database, but because that is what needs to happen for the application to make sense. We can't update the balance if we don't get to fetch an account.
We mix application and business logic - two different responsibilities within the same class and method. One is responsible for orchestrating what needs to happen in the application and the other for executing the business rules. The lack of separation makes the codebase harder to maintain and understand, increasing the risk of introducing errors.
Inconsistent Domain State
Let's (again) look at the TransactionService class:
public class TransactionService {
//Code...
@Transactional
public void create(double amount, String vendor, String accountNumber) {
var transaction = new Transaction(amount, vendor, accountNumber);
accountService.updateAccountBalance(amount, accountNumber);
bonusService.generate(transaction);
transactionDao.save(transaction);
}
}There's another issue that many will miss: We allow for an inconsistent state within the domain.
The business rules state that we must update the account balance when a new transaction is created - but our code doesn't express that. We create the transaction, and then we update the balance. What stops some other class from creating and pushing a new transaction to the database? Nothing!
It also looks like we can change the balance without necessarily creating a new transaction - which is also something that should never happen.
Nothing stops us from creating a new transaction and storing it in the database without generating a bonus.
You might say "No you can't; the create method doesn't allow it", but that assumes that everyone is using the create method. Assuming that this is a real banking application, it is doomed to grow in complexity and size. The system will be extremely difficult to keep track of everything - and you just have to know that these things need to happen and that you need to call TransactionService.
The issue is that it isn't that easy. Suddenly there's a new requirement, and a new service is created that simply creates the Transaction object and saves it to the database. It might not be incompetence or malice but a simple case of not remembering it.
Some might argue that this wouldn't happen and would be caught in pull requests. I disagree because I've seen it happen. Not within banking, but developers forgetting to call that one magical method that orchestrates some important behaviour is something that I've definitely seen.
The point is that we should make sure that we can't have inconsistent domains. That removes cognitive load when developing, and we reduce the risk of something as "forgetting to call a method" to introduce massive problems.
SRP Challenges: Violating the Single-Responsibility Principle
In the previous section, I argued that allowing for inconsistency within domains is bad and leads to more issues.
Given that we have to remember to call a specific method to ensure that we get specific behaviour we quickly run into issues with SRP that states:
The single-responsibility principle (SRP) is a computer programming principle that states that "A module should be responsible to one, and only one, actor."
How can we do that if everything must be, in this case, funnelled through the TransactionService? We can't. The only way to avoid violating SRP would be to copy code around - which is also not ideal.
To avoid SRP violation, developers duplicate code or create new classes to handle specific scenarios. However, these decisions are often driven by the constraints of the architecture rather than sound design principles.
Going Against Object-Oriented Programming (OOP)
Some people might not find this argument compelling. Why would it be important whether something is "true" OOP? What matters is whether it is a good design and works well! And I totally agree. I'm no OOP knight in shiny armour, which requires everything to be OOP by the letter. I do believe this is something to be aware of.
Back in ye olden days, we had very few constrictions regarding access. We could access any data and code that existed in memory at any point. Then Djikstra graced us with "Go To Statement Considered Harmful". Through that practice, we discovered that limitations might be a good thing. By not using "GOTO" as a way to jump to any piece of code willy-nilly, our applications became easier to understand and debug. The flow of the applications became easier to follow, and as a result, we produced fewer bugs.
At some point, we realised that data and functionality are interlinked. Some functionality only makes sense when coupled with the data - and some data only makes sense when coupled with the right logic. The need to combine data and logic turned into OOP.
When we have anemic models we aren't combining data and logic - we're separating them again. But again, why does this matter?
It matters because it contributes to the problems we've already discussed, as we're essentially writing procedural code in an OOP language. We're not using the power that OOP provides to our benefit (we'll get into how we can do that later).
I would argue that if one primarily has anemic domain models and uses an OOP language, then one doesn't understand OO principles. Nor do we get the benefits that OOP offers.
Rich Domain Models: A Better Alternative
Up to this point, I've made arguments as to why I believe anemic domain models are a problem. This is a valid argument, so let's do that!
When discussing anaemic domain models, it is easy to go down rabbit holes - primarily related to domain-driven design (DDD). I will use concepts from DDD, but I won't go into too much detail. This is not a post about DDD.
The counter to anemic domain models is rich domain models: Classes that combine data and logic. If we host all the business rules with the data, we end up with a more robust solution. By splitting up application and business logic, we get easier to reuse code.
More importantly, we end up with a domain that won't allow itself to be corrupted. When using anemic domain models, there's no validation or checks - at least not initially. There might be checks at some point, but if we remember back to our Account class, there was no direct enforcement of anything. We're essentially allowed to do whatever with that class, and either a framework or the service classes handle whether or not the state is correct.
With rich domain models, we ensure the state is always correct. We should not be allowed to set the models in an illegal state. To do that, we must move a lot of the business logic into the domain models themselves and rethink how we structure them.
Rich Domain Models in Practice
Let's go back to our Account class. This is how it looked originally:
@Entity
@Table(name = "accounts")
public class Account {
@Id
@Column(name = "account_number", unique = true, nullable = false)
private String accountNumber;
@Column(name = "balance", nullable = false)
private double balance;
public Account() {
}
public Account(String accountNumber, double balance) {
this.accountNumber = accountNumber;
this.balance = balance;
}
public String getAccountNumber() {
return accountNumber;
}
public void setAccountNumber(String accountNumber) {
this.accountNumber = accountNumber;
}
public double getBalance() {
return balance;
}
public void setBalance(double balance) {
this.balance = balance;
}
}Let's see what happens when we "enrich" it:
@Entity
@Table(name = "accounts")
public class Account {
@Id
@Column(name = "account_number", unique = true, nullable = false)
private String accountNumber;
@Column(name = "balance", nullable = false)
private double balance;
public Account(String accountNumber, double balance) {
setAccountNumber(accountNumber);
setBalance(balance);
}
public String getAccountNumber() {
return accountNumber;
}
public double getBalance() {
return balance;
}
private void setAccountNumber(String accountNumber) {
if (accountNumber == null || accountNumber.isEmpty()) {
throw new IllegalArgumentException("Account number cannot be null or empty.");
}
this.accountNumber = accountNumber;
}
private void setBalance(double balance) {
this.balance = balance;
}
}So what changed? For one, we no longer have public setters and removed the empty constructor. We also added some validation.
This matters because now we can't even initialise the Account object without it being valid - let's take it a step further. Remember, we also have to support transactions:
@Entity
@Table(name = "accounts")
public class Account {
@Id
@Column(name = "account_number", unique = true, nullable = false)
private String accountNumber;
@Column(name = "balance", nullable = false)
private double balance;
@OneToMany(mappedBy = "account", cascade = CascadeType.ALL, orphanRemoval = true)
private List<Transaction> transactions = new ArrayList<>();
public Account(String accountNumber, double balance) {
setAccountNumber(accountNumber);
setBalance(balance);
}
public String getAccountNumber() {
return accountNumber;
}
public double getBalance() {
return balance;
}
public void addTransaction(double amount, String vendor) {
if (amount == 0) {
throw new IllegalArgumentException("Transaction amount cannot be zero.");
}
var transaction = new Transaction(this, amount, vendor);
transactions.add(transaction);
this.balance += amount;
}
private void setAccountNumber(String accountNumber) {
if (accountNumber == null || accountNumber.isEmpty()) {
throw new IllegalArgumentException("Account number cannot be null or empty.");
}
this.accountNumber = accountNumber;
}
private void setBalance(double balance) {
this.balance = balance;
}
}The main thing happening here is that we now have the addTransaction method. It should probably be called something else, but for now, it'll do.
Here we see a continuation of not allowing the domain to become inconsistent. If we take a look at the Transaction class, we see this enforcement continued:
@Entity
@Table(name = "transactions")
public class Transaction {
//Properties...
protected Transaction(Account account, double amount, String vendor) {
this.account = account;
this.amount = amount;
this.description = description;
}
//More code...
}Here we see that the constructor uses Java's protected keyword - meaning that nothing outside the module can initialise this class. If we put all these rich domain models within their own package, we essentially remove the ability to magically create new transactions - which is what we want in this case.
Now, let's talk about the bonus requirement. Whenever we create a new transaction, we also need to run some checks and potentially generate some bonus. I don't want to get too bogged down with DDD in this post, but it is important to consider the boundaries of our classes. In this case, it is fair to ask whether bonus is actually directly related to the concept account and transaction? It is certainly derived from transaction, but it isn't directly related. It is something that may happen as a result of a transaction being created, but that is about it. This is a great place to invoke some eventual consistency!
If we were to create our entire application as we have done above, we'll end up with some mighty complex structures - which we want to avoid. We want to come up with something better than anemic domain models; as such, we must employ some new tools. One of those tools is domain events.
Bonus is a great candidate for a domain event. The business requires bonus to be generated when we create a new transaction, but we're probably not limited to it being created in the same transactional scope. We can use domain events and eventual consistency to do the job - decoupling the code that creates transactions and bonuses.
Let's see how we can do that within our Account class:
@Entity
@Table(name = "accounts")
public class Account extends AbstractAggregateRoot<Account> {
//Code...
public void addTransaction(double amount, String vendor) {
if (amount == 0) {
throw new IllegalArgumentException("Transaction amount cannot be zero.");
}
var transaction = new Transaction(this, amount, vendor);
transactions.add(transaction);
registerEvent(new TransactionCreatedEvent(this.accountNumber, amount, vendor));
this.balance += amount;
}
//Code...
}I'm using Spring's event implementation here. There's no single "correct" way of sending events. I just so happen to do it this way now for the sake of simplicity. For this example it doesn't matter how the event is distributed - it could be using a custom queue implementation or some other third-party event solution. It can even be an external system such as Kafka.
We have removed a lot of complexity from the addTransaction functionality. After all, it doesn't need to know about bonus. That is not to say that there's no tradeoff. Whenever we introduce "eventual consistency" we also introduce a bunch of complexity. But I strongly believe we end up with a codebase and system that scales much better.
For example, remember the case where we should be able to redeem bonus points to the accounts? Now this can be an event as well! Account and Transaction never need to know anything about bonus, nor does bonus need to know anything about them!
Do note that if it was really important that the concept of bonus and transactions being linked, then that would be possible. The cost would be added complexity within these rich domain models. It is also worth mentioning that we decided to decouple the bonus functionality because it resulted in a cleaner solution - not because we had to.
Rich Domain Models and Services
So far we've tackled the domain and made sure that the domain is consistent. But what about the TransactionService? We have removed the ability for anything outside the "domain" module to even create the object. Something has to change, right? Absolutely!
It is important to consider that we're now dealing with what is called a root aggregate - The root aggregate is the Account class. I.e. the class that encompasses the domain. We wouldn't have a TransactionService. Instead, we'd have an AccountService, which would look like this:
public class AccountService {
private final AccountDao accountDao;
public AccountService(AccountDao accountDao) {
this.accountDao = accountDao;
}
@Transactional
public void createTransaction(String accountNumber, double amount, String vendor) {
var account = accountDao.find(accountNumber);
account.createTransaction(amount, vendor);
accountDao.save(account);
}
}Guess what - the AccountService now looks like our first version of the TransactionService! This is not by accident. When moving over to rich domain models, we get a separation between application logic and business logic. The application logic was pretty simple: Find the correct account, trigger the domain logic and save. Services become orchestrators - they fetch data, call third-party services, do everything necessary to satisfy the domain models, and then persist the result (if desired).
Why Rich Domain Models are Preferred
The text above can be daunting, so I wanted to briefly summarise the benefits the model above gives us.By using a rich domain model, we get the following benefits:
- Enforcing business rules: By having a model that enforces its correctness we end up with a safer system to change. We should be unable to put any domain model into an invalid state.
- Decoupling concerns through domain events: We identified that "bonus" is a different concern than "account" and "transactions". By realising this and approaching a more DDD-centric style, we decoupled these two concerns to the point that they don't need to be in the same system.
- Decoupled application and business logic: In the anemic approach, there was a strong coupling between what the application had to do and what the business rules dictated, which resulted in a codebase that could not scale in complexity. By using rich domain models, we managed to separate the two concerns.
Why Anemic Domain Models Persist
Despite the drawbacks and issues associated with anemic domain models, they continue to be prevalent in software development. Several factors contribute to their persistence.1. Anemic Domain Models are the Path of least Resistance
One of the main reasons for the prevalence of anemic domain models is the simplicity they offer on the surface. Implementing anemic models seems easier and requires less thought. Developers can quickly achieve results, especially in new codebases. Additionally, anemic domain models work naturally with Object-Relational Mapping frameworks, making them a convenient choice.2. Layered Architecture Encourages Anemic Domain Models
Another factor is the most common architecture: Layered architecture (N-tier architecture). Layered architecture has some similarities to attributes of anemic models when we look at why it is so popular. For example, it tends to be the default separation people come up with. After all, APIs are their own thing, and they should be separated from business logic - which again should be separated from the database stuff. Another comparison is that it is a simple architecture that is easy to reason about. As it is mostly obvious, one rarely has to be burdened by questions about what goes where. Layered architecture is chosen due to its simplicity and approachability. Developers often ignore that it struggles to scale with complexity.Another attribute layered architecture has is that it doesn't have a lot of opinions. Other architectures like Clean or Hexagonal come with many rules and push developers in certain directions. Layered architecture simply directs what something may depend on (and even then it doesn't have very strong feelings over it). Being so unopinionated forces the burden to make good decisions onto developers/architects - which often takes the path of least resistance (aka anemic domain models).
For example, there's nothing in layered architecture that requires a separation between business logic and application logic - more often than not, that responsibility is pushed into the same layer named "Application".
3. Architecture Tends Not to Evolve
YAGNI is a saying that a lot of developers are aware of. It is the same with premature optimisation. As a field, we have had a habit of making things unnecessarily complex in an attempt to future-proof our systems. It rarely works and often causes other issues. We're trained to Keep It Simple, Stupid (KISS).Most of us probably know that codebases tend to grow in complexity and size over time - especially if the software sees actual use. If we follow regular developer/architecture advice when initially creating the system, we'll probably end up with a layered architecture and anemic domain models. As the system outgrows its design, the issues start revealing themselves. While rearchitecting to address these issues may be beneficial, developers often continue with the existing design due to the perceived costs and effort associated with such changes.
4. Lack of Awareness
Sometimes it can be difficult to identify why something is difficult. This happened to me when I used anemic domain models: I built a system that did something, and eventually, I ran into the scaling issues that come from layered architecture and anemic domain models. I perceived neither to be the culprit. I believed the application's responsibility was too big - it was doing too much! The solution was obviously to split it up!Splitting up such a system can help on a low level, but it isn't a solution. What we instead end up happening is that we're pushing the complexity of the domain into the infrastructure. We're complicating how systems need to communicate to achieve things that shouldn't be that complicated.
Why did I do this? The reason was that I didn't know about rich domain models. I had never been exposed to them. I didn't know any better. This has been my experience when talking to other developers as well: A lot of them do not have any experience with rich domain models, DDD, hexagonal architecture, etc. They don't see anemic domain problems as problematic because they've never even heard the term - much less explored alternatives. There's a real lack of awareness surrounding not only anemic domain models but also DDD and alternative architectures.
From Simplicity to Elegance
Developers and architects want to create good systems that can be maintained and expanded upon. We want our systems to express professionalism and technical excellence. Anemic models, while initially alluring due to their simplicity, often results in codebases which are challenging to maintain - and sometimes lead to costly rewrites when projects become too unwieldy. There's a reason Martin Fowler describes anemic domain models as an anti-pattern, because they are.Rich domain models represent a much more compelling way to express business logic. They encourage code reuse while making a codebase which protects developers from silly mistakes. The main tradeoff is that rich domain models require active thinking and design, while anemic domain models require workarounds due to the lack of design (which I suppose is a form of creativity, but I digress).
Do everyone a favour: Do not use anemic domain models. Or to quote Martin Fowler:
In general, the more behavior you find in the services, the more likely you are to be robbing yourself of the benefits of a domain model. If all your logic is in services, you've robbed yourself blind.
Special thanks to Christoffer Karlsen for proofreading and providing valuable feedback