I’ve been very busy with architectural decisions, developer processes, and the like up to this point in my career. I never really had a deep dive into the world of authorisation. It has always been a part of the systems I’ve worked on, but never really something I considered to be much different than regular business logic - it is all if and else statements, after all. It is all just code that our applications need to fulfil their purpose, nothing special about it!
Turns out, though, I was very wrong, or at least very ignorant. Yes, authorisation can be represented by if and else statements, but the impact of how one decides to implement authorisation can have broad and long-lasting consequences.
This all started when I was browsing through code to better understand Spring Security and happened to land on some code that did authorisation, where I stopped for a second. Turns out that there were multiple classes (regular, utility, DAOs, etc.) while powered by Spring beans and annotations. My initial thought where “This is a lot for something that should just be if and else statements”. There was nothing wrong with the implementation itself - it was clean, maintainable, had tests and all. But it was a lot. Then it dawned on me: It wasn’t a lot because there was actually a lot of code or that it was overly complicated. It was a lot because I live in a world of microservices. Having every service be responsible for their own proprietary implementation of authorisation completely removes the ability to quickly verify, report and review authorisation across the solution. Even worse, there will be a lot of duplicated code to check for the same stuff. While Spring Security is excellent, every single application must implement the necessary scaffolding to get Spring Security up and running.
After realising this, I started to look into what alternatives existed, at which point I fell into the rabbit hole of authorisation. I started looking for a list of standard approaches to authorisation, but I had trouble finding a decent overview. I decided to document the methods I find, which has turned into this very post.
NOTE
Unfortunately, I had to cut stuff for this post, or else it would be too large. I wanted to aim for a post that goes over the basics of authorisation and a general overview of the various patterns I've found, so something had to go.
The main thing I had to cut was an in-depth description and discussion of access controls. There are multiple types, such as role-based access control (RBAC), property-based access control (PBAC) and authorisation tokens. The patterns outlined in this post isn't concerned with what type of access control is at play and should work with either. Some minor adjustments might be needed, but overall the patterns should be access control agnostic.
If you want to delve further into the impact of the various access controls and how they relate to distributed computing. In that case, I can recommend Ekaterina Shmeleva’s master’s thesis, “How Microservices are Changing the Security Landscape”. While not a be-all and end-all guide on the subject, it is a great introduction and the sources leads to further reading.
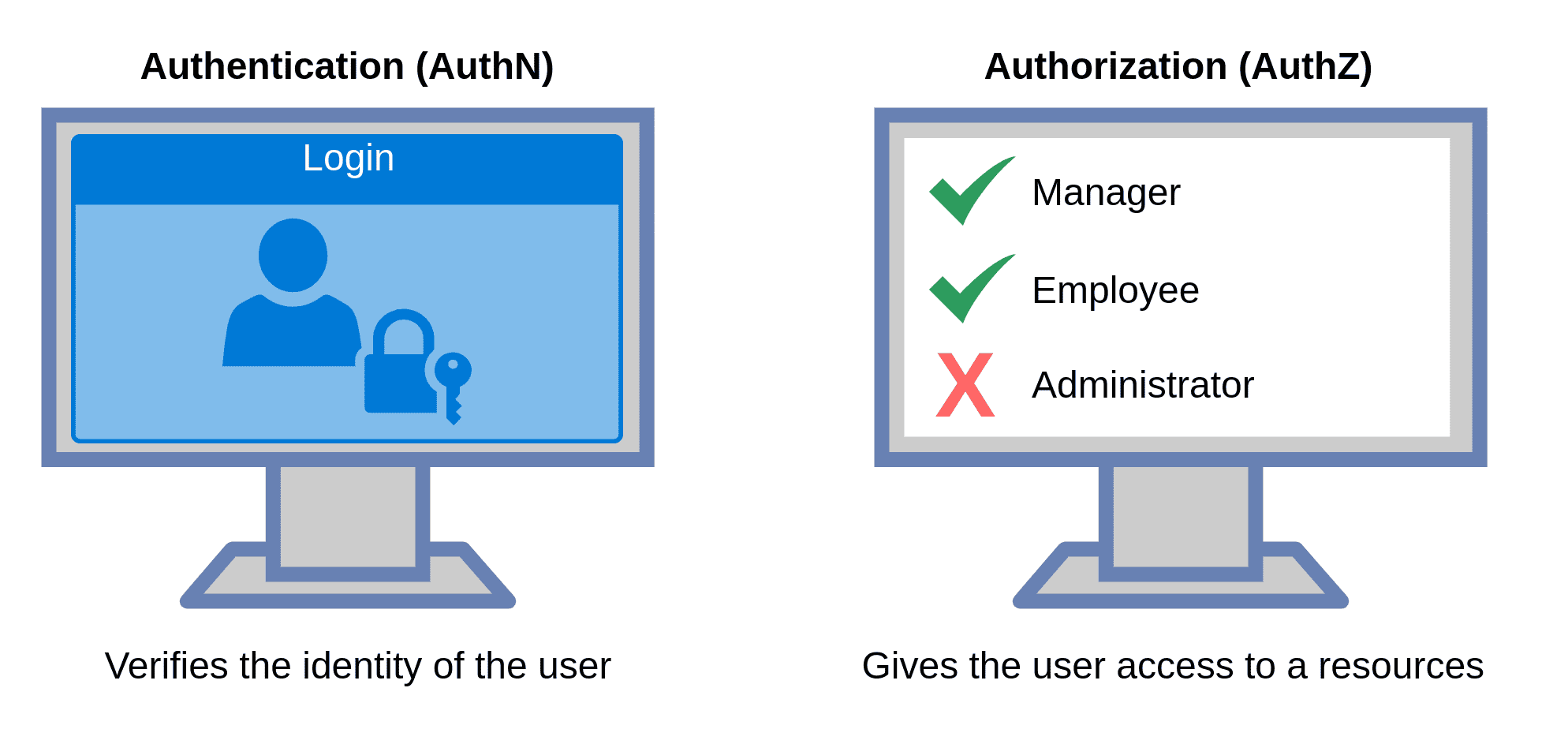
Before getting into the nitty gritty part of AuthZ we should probably make sure that we're on the same page of what AutZ actually is.
The most common confusion of AuthZ is when it comes to AuthN (Authentication). These are to completely different processes. Where AuthN verifies identity, AuthZ verifies Access.
AuthZ can be implemented in a variety of ways, but it is always represented by a policy. A policy is a “rule” the system has to follow to be compliant. Here’s a few examples of what a policy can look like:
Policies are the rules that determine access to some data or operation in the system. Many companies do not have explicit policies written down. Still, as long as some code enforces access to a resource, there’s a policy attached to it (even if it is undocumented).
Policies can have many shapes, but at their most basic level, they can be represented by pure code:
public boolean canEditPost(User user) {
return user.isAdmin();
}
Authorisation is an integral part of the software we write, and it is vital to the company’s existence. We have to have some relationship to authorisation, or we don’t have a product that generates money. However, let’s get a little more concrete.
I used to work on healthcare systems, and we needed to give away healthcare information only to people that should see them. A physician should see their own patients journals, but not the patients that belong to other physicians. Without this functionality, we wouldn’t have a sellable product.
When a breach happens, we have to figure out what happened and what went wrong. Sometimes authorities or big customers get involved and demand answers. There are also industries, like banking, that has yearly compliance checks and security audits. In these situations, we need to get an overview of all the authorisation happening across the entire system, and we must be able to communicate in a way that makes sense.
There’s more to authorisation than security and compliance because the logic that checks for authorisation must exist somewhere. It is logic that must be maintained and changed as applications change.
To take it even further, authorisation impacts the flow of data. It is not uncommon to have long and complicated flows of data in larger systems. In a large and distributed healthcare system, we have to ensure that no other application leaks patient data, not just the journal application.
When we bundle these aspects, we find that authorisation is a core concern for pretty much any business. It impacts the code developers write, the infrastructure that runs those applications, and the business as a whole if the approach to authorisation isn’t flexible or understandable.
When starting to look at options for AuthZ is that perfect AuthZ doesn’t exist. There’s simply too many variables and trade-offs between the approaches we have today, and we always end up having to make tough decisions.
Nevertheless, that doesn't mean that we cannot have a look at what traits an ideal AuthZ implementation would have:
AuthZ should be maintainable for the developers working on the protected application: In traditional AuthZ implementations, the logic is found within the application itself, in whatever language the application is written in. This approach is straightforward for developers to manage. There are a few factors that can impact the maintainability of the application:
AuthZ should be traceable: An AuthZ implementation should tell us what is doing and why. We should be able to answer why access was approved or denied, and even potentially who the request related to in the first place. This can be crucial data in case of breaches. A good AutZ implementation will tell you who can access what data, both right not and for 6 months ago.
The AuthZ logic should support all protocols in use: implementation should protect all the interfaces of an application, be it through FTP, Kafka, HTTP and so forth.
It should be easy to collect policy data: An AuthZ implementation should provide extensive, detailed, accurate and up-to-date reports of the policies in the solution and how they’re handled.
Global changes to policies should be easy: A company should not be held back by the AuthZ implementation. If a company goes into a new country, then extensive rewrites shouldn’t happen in the system because the policies must account for a new country code. If a role is deprecated, it should be easy to roll out changes that actually deprecate that role in the various systems.
Policies should be verifiable: We should be able to write automated tests to verify a policy.
As it stands, no implementation ticks all the boxes. There’s always a trade-off, and when looking at solutions, one should keep in mind which aspects are more important than others.
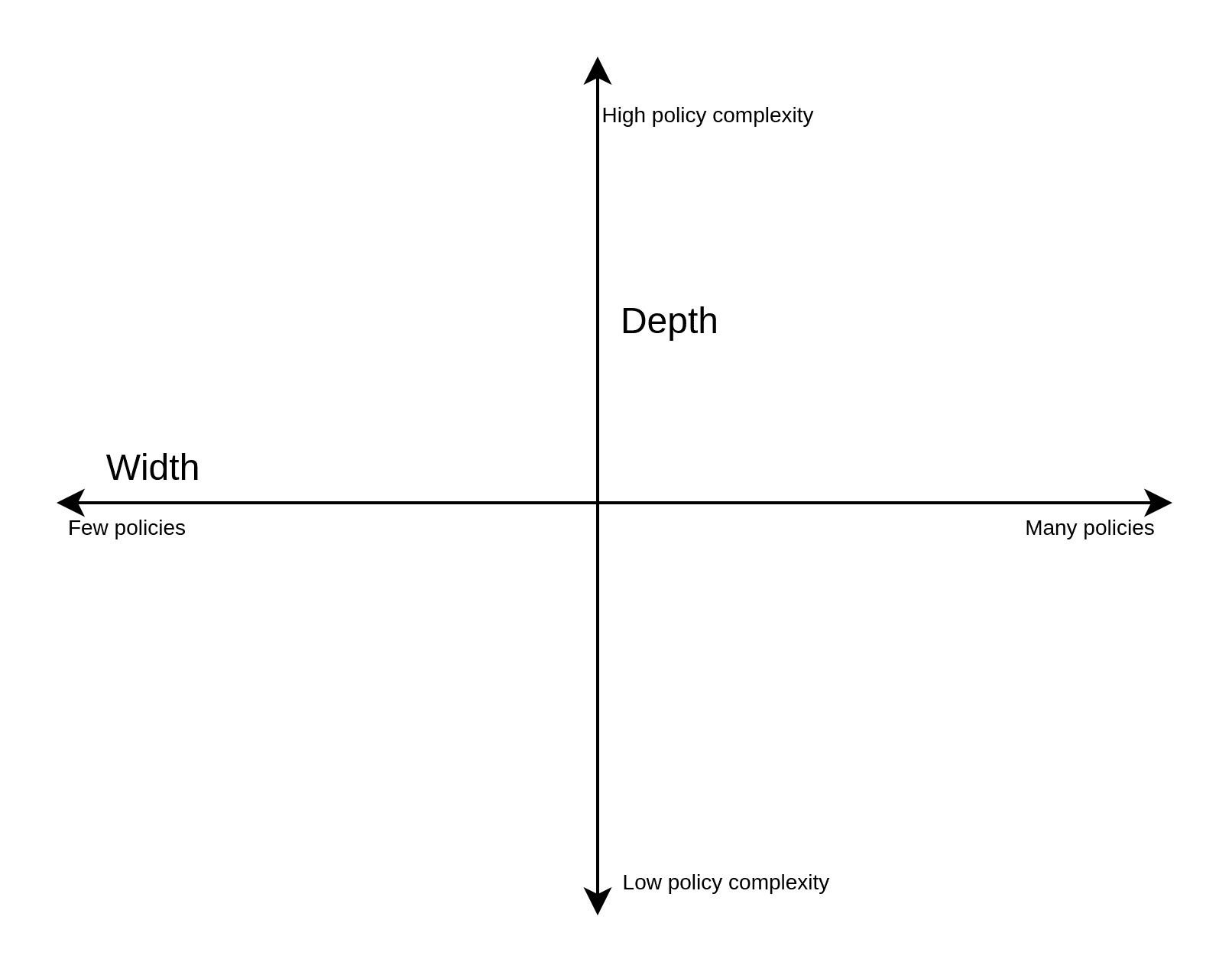
One thing to consider when figuring out how to approach AuthZ is the width and depth of policies required. The width can be viewed as the number of variables that makes up the policies, while depth is the complexity of those variables.
Let’s consider an example where we have a blog called “Headphone Phanatics”. In this blog, we have a post service that is responsible for serving all the blog posts. Currently, the only actions available are:
LIST: Lists all blog postsGET: Gets a single blog post by IDThese are both public endpoints, so no AuthZ is really required. However, we need to create, edit and delete posts as well, so let’s introduce the role of an author. We now have two roles in our system (Author and Reader), and our endpoints and its required AuthZ looks like the following:
LIST (All): Lists all blog postsGET (All): Gets a single blog post by IDUPDATE (Author): Updates a blog postCREATE (Author): Creates a blog postDELETE (Author): Deletes a blog postBy introducing the role author, we haven’t necessarily added much complexity to the Authz logic. Still, we have increased the number of roles or variables that needs to be managed. We could add more roles to increase the number of variables or width.
Our blog does really well, and people love our headphone content, so we need to hire more authors. When there was a single author, the posts were written on the computer and uploaded as a whole. Now that the blog grows, we need to add the concept of drafts that only users with the role of Author can read:
LIST: Lists all blog postsGET: Gets a single blog post by IDUPDATE (Author): Updates a blog postCREATE (Author): Creates a blog postDELETE (Author): Deletes a blog postNow there’s more complexity to the call. We see that both Authors and Readers can access the GET endpoint, but there’s logic tied to which post they’re allowed to see. Previously it was easy to do the AuthZ externally to the application as there was no need for extra information to make a judgement. We could tell whether a user should have access or not by the endpoint and role alone. Whether a specific post is a draft or not, the information is stored within the post-service itself. If we want to have our AuthZ external to the application, we must get hold of that data somehow, or we can have the service handle its own AuthZ internally
Let’s say that our blog wants to start doing reviews, but to get headpones prior to release we have to sign embargos. First, we want to make sure that our contract is digital, so we don’t lose it. We also want to structure some information so that we can quickly see when something can be released. As a result, we create the embargo service that holds these documents and connects them to a post stored in the post service. Ignoring the security complexities of such a service, let’s just assume that only Authors can access this service:
LIST(Author): Lists all embargosGET(Author): Gets a single blog embargo by IDUPDATE (Author): Updates an embargo postCREATE (Author): Creates an embargoDELETE (Author): Deletes an embargoWe see that the embargo and blog post services share several policies, and it would be great if we could re-use them to cut down on code that needs to be maintained. However, there is AuthZ logic in the post-service that is closely coupled with the data it contains.
We see that the wider the policies are, the more we want to centralise the AuthZ implementation. However, with deeper (complex) policies, we generally want to keep them localised to their respective applications. If we try to keep complex policies centralised, we end up with an AuthZ implementation that can be very difficult to maintain. However, if we have many variables at play, it will become difficult to maintain if we allow each application to implement its own AuthZ.
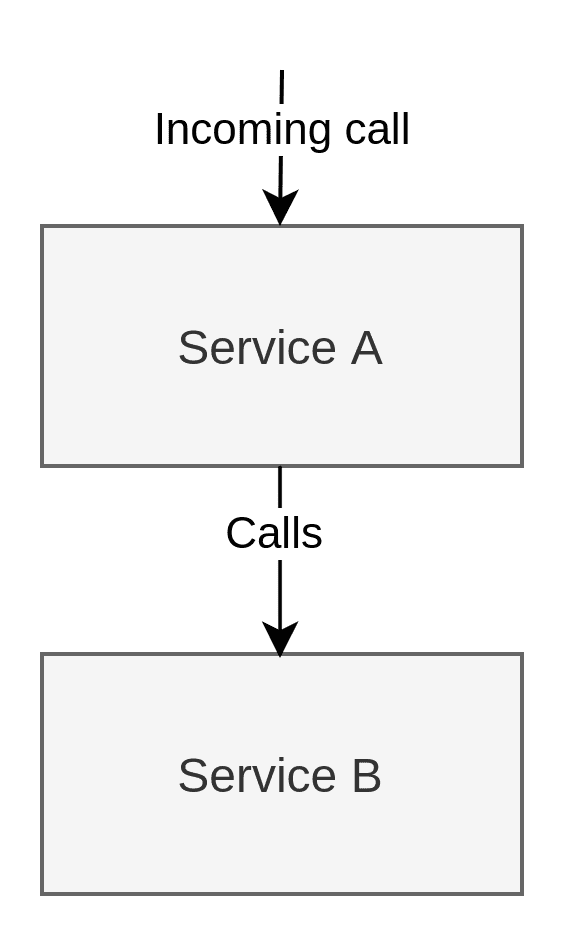
In our example, we have 3 services, Service A, B and C. It doesn’t matter whether they’re web services. This scenario focuses solely on the dependency between these services, not the protocols they use to communicate. They can be separate applications that transfer FTP files, REST services or whatever you can imagine.
In our example, the user will call Service A, but to complete the processing, Service A needs to call Service B to get some information:
To authorise the user, both Service A and Service B need to gather some information from Service C. This is arbitrary and arguably bad design. However, the real world is messy, so I introduced some messiness into the example. What data Service C contains isn’t essential. It could be information about the user’s permissions/roles or some data regarding ownership of these systems’ data. It is not a pattern I’d intentionally go for, but it is one that I’ve seen happening before:
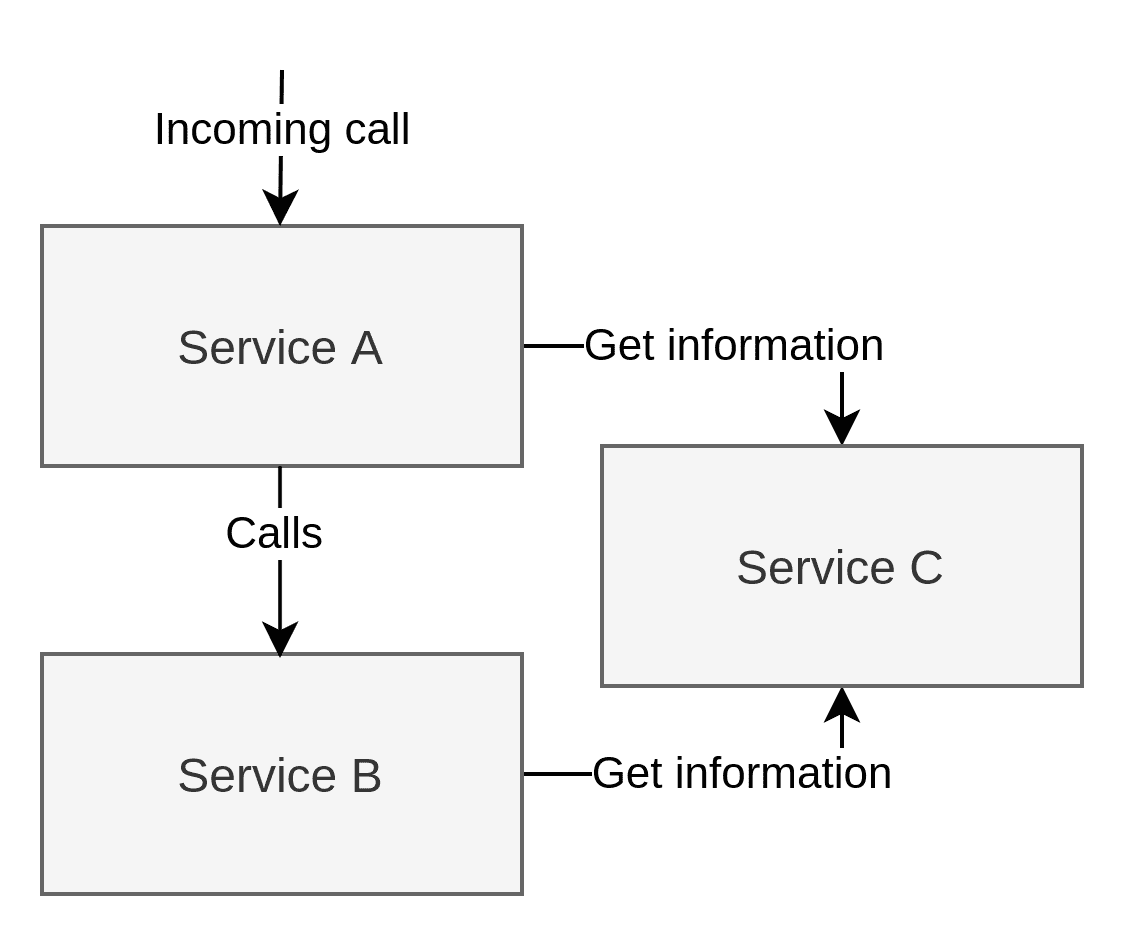
To recap, Service A needs to call Service B to fulfil the request from the user, while both Service A and Service B must call Service C to get the data they need to authorize. This is the example that is in use when looking at the various authroization patterns.
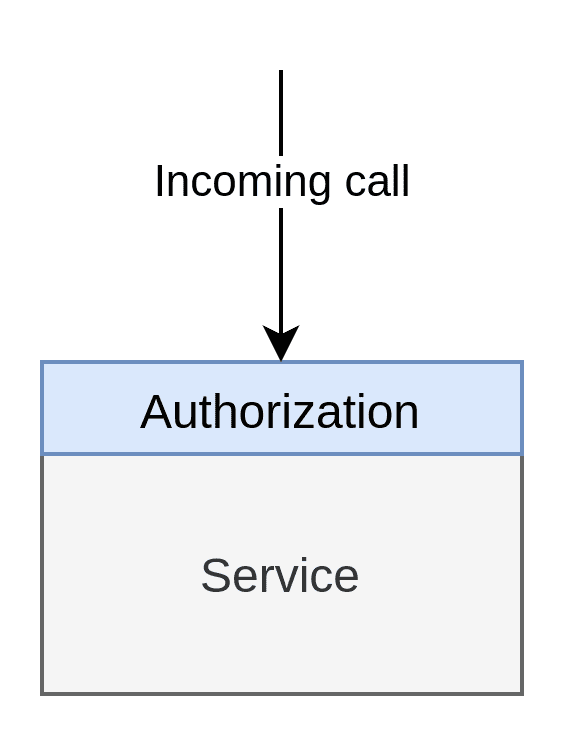
When we say native, we’re actually saying native to the application’s source code. I.e. the code is handled within the application itself in its native source code. A Java application would have its policies written in Java, Python in Python and so forth. As far as I’m aware, this is the most common way to handle AuthZ. It can look something like this:
public void throwExceptionIfUserIsntAuthorizedToReadAccount(User user, Account Account) {
//Owners of the account is allowed to see the account
isOwner = isUserOwner(user, account);
//Employees from the same country is allowed to see the account
isAuthorizedEmployee = isAuthorizedEmployee(user, account);
if (isOwener || isAuthorizedEmployee)
return;
throw new NotAuthorizedException("User don't have access to this acount");
}
public boolean isUserOwner(User user, Account account) {
return user.id() == account.owner();
}
public boolean isAuthorizedEmployee(User user, Account account) {
return user.isEmployee() && user.country() == account.country();
}
The code above is arbitrary, but the point is that this kind of logic is what we often see. There’s if statements and returns. The maturity and execution of this kind of AuthZ might differ, but some code does these checks somewhere in the application.
In this pattern, we might also use libraries or frameworks to help us. We have Spring Security for JVM languages, where a lot can be injected and autoconfigured to help write better AuthZ. The AuthZ enforcement happens in the application’s source code at the end of the day.
You generally want to use the Native Authorisation Pattern when building a monolith where you only have to worry about protecting the monolith, and doing so natively is the easiest and most manageable. Since it is just a single large application, all authorisation will be found in a single place anyway, so you avoid many of the issues highlighted previously in this post.
AuthZ becomes much more complicated when we introduce our example, which consists of 3 services:
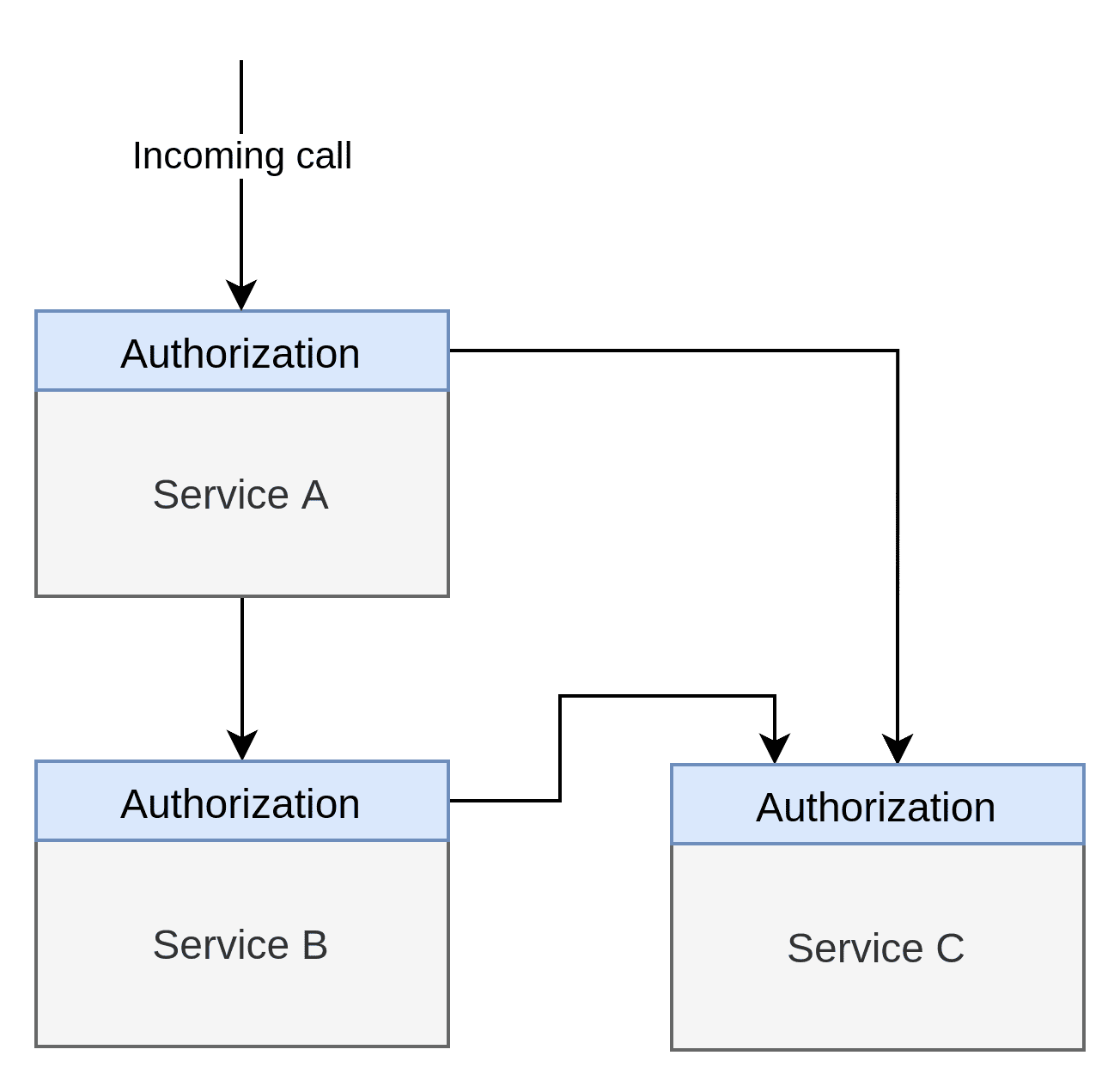
We see that Service A and Service B must individually call Service C to get the information they need, and they must conduct their own AuthZ separately. For all we know, there could be different teams working on Service A and B, and there are no guarantees that these teams share the same understanding of what the various roles or properties mean. It is definitely possible that Service B gives Service A some information due to some misunderstanding. Equally likely is that Service B denies access to Service A.
The Native Authorisation Pattern is as internal as we can get. To truly know whether the AuthZ policies are enforced and to what degree, we have to read the source code. This isn’t a huge problem when you only have a few services, but it can be a massive time-sink if you work with a substantial microservice solution.
Let’s say you work for a major company within your country that works for the government. One day the company has a data breach. In response, the government comes knocking and demands a throughout report on how the breach could happen and the current state of your security. That report includes a deep dive into how the company manages AuthZ and whether the applications adhere to the policies. In this day and age, it is fair to assume that this is a microservice or distributed-monolith, so let’s say that you have around 300 services. In these situations, the company assemble an emergency team to deal with this report. One of the people from this team goes to you and says, “Provide us with an overview of who can access what”. How would you handle that?
The only thing we can do in the situation above is simply to go through and read the source code for all 300 services. Obviously, we will split up our workflow on the various teams, but it will be a considerable undertaking nonetheless. The example above is an uncommon scenario for most people, but consider that many companies do these kinds of reviews every year, if not a few times a year. Furthermore, this also ties back to making changes to the policies. When things are added, removed or changed in the policy, we must also b
We see that the number of applications correlates to how time-consuming and difficult it is to make changes and get the actual state of our policies. Note that I’m not saying this is “the wrong” way of doing AuthZ with microservices, but it comes with some significant trade-offs.
Native Authz is, on the other hand, very maintainable for the developers themselves. For them, it is mostly business logic, which they already know. It is already in a programming language they know, and since it is a part of the source code, they have ownership over the policies for their applications.
Internal Non-Native AuthZ is very similar to Native AuthZ except that it is written in another language or uses a framework/library that forces another language.
I mentioned Spring Security in our previous example, but Spring Security does not force people out of Java (or whatever JVM language they use). There are libraries like OSO that the application uses and feeds all the information it has, but in the case of OSO, the policies are written in a language called Polar.
If we take our native Java example above and translate it to Polar, it will look something like this:
# Allow if user is owner of account
allow(user: User, "read", account: Account) if
user.id = account.owner;
# Allow if user is employee of the same country as the account is registered
allow(user: User, "read", account: Account) if
user.isEmployee = true and
user.country = account.country;
The Java application must still call Oso at some point, though:
oso.is_allowed(user, "read", account)
Therefore, we cannot remove all bloat from the application, but we can get to a point where the application code can become very much standardised.
The downside of internal non-native AuthZ patterns, in general, is that the business logic is split up between two languages. The code is still in the repository, and the developers are still in control, but they have to contend with a slightly more complex tech stack.
The benefit, however, is that all policies will be understood across the board as they’re all expressed in the same way with the same expression. Using a library encourages applications to gather all the information they need and then do a full AuthZ check. In native AuthZ, developers can spread out the AuthZ logic wherever they like. We are essentially limiting developer freedom and some maintainability for standardisation.
Additionally, since every policy is written separately to the application, they can be uploaded to a centralised location, making them available for reporting and verification.
A major downside for some might be the fact that there’s limited support of languages. Oso, for example, supports Node, Python, Go, Ruby, Rust and Java, but if your tech stack falls outside these, you have to start mixing up AuthZ or bridge the technologies. Both adds complexity to the solution.
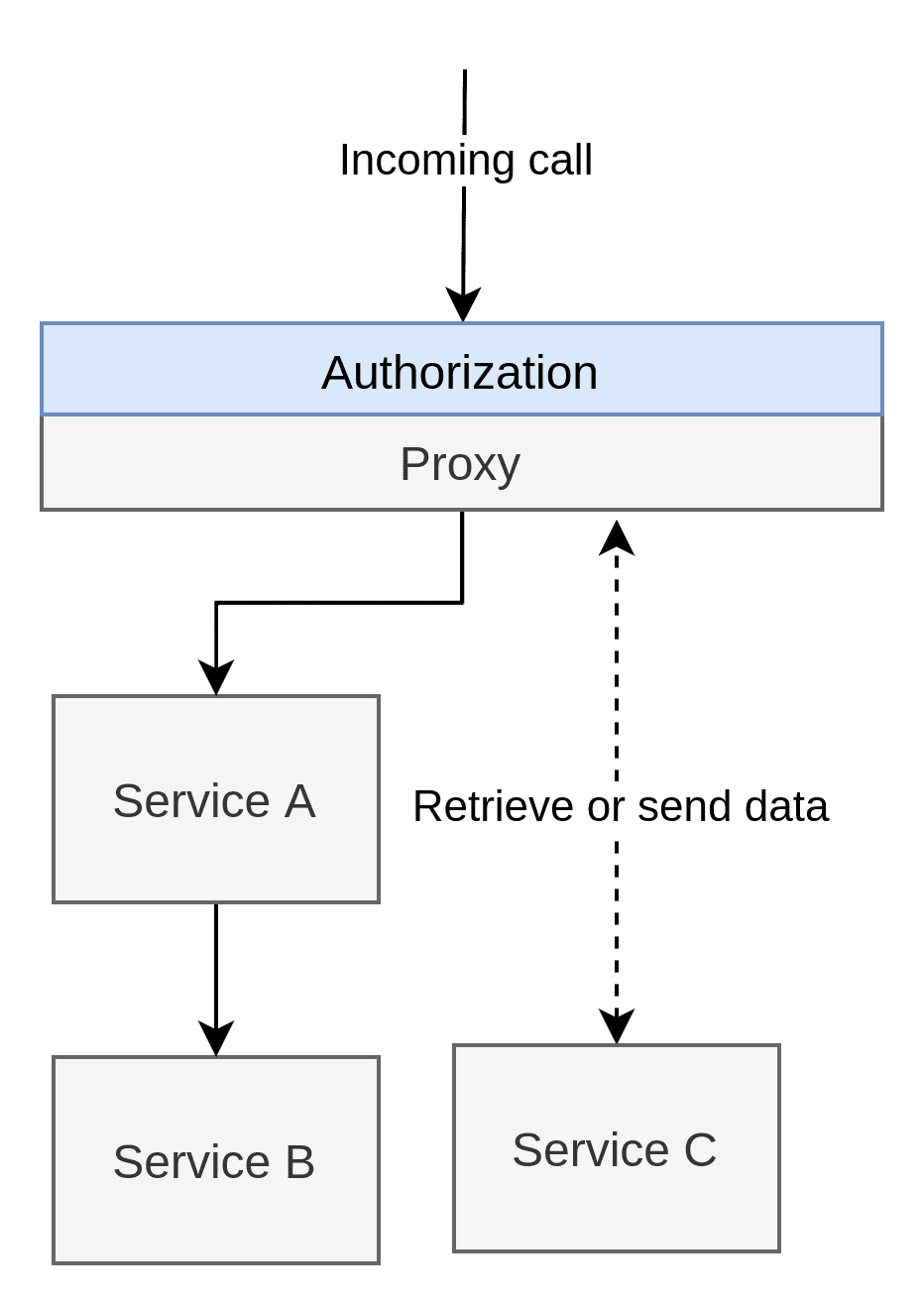
Let me start this off with a PSA: NEVER USE THE PROXY PATTERN. Don't create secure networks (or "safe zones"). This is fallacy number 4 on the list of "Fallacies of distributed computing", and it is on the list for a good reason. I will get more into this later in this section, but I wanted to start with a warning.
As the image above shows, the proxy pattern moves all AuthZ complexities to a single application and “protects” the environment behind it. Whether the policies within the proxy is handled natively or not doesn’t matter. The point is that everything behind the proxy is considered a safe zone where AuthZ isn’t a concern.
The few good things I can say is that all the policies will be located in a single location, which means global changes will be easier. The other benefit is that all AuthZ complexities have been removed from all the services behind it to purely focus on managing data and not worry about security.
There are many reasons why you should never use the proxy pattern; it becomes challenging to maintain. The individual applications might be slightly easier to maintain since they don’t have to worry about this logic, but the proxy has to worry about all the logic. Worse, the proxy has to know about each application and understand what is needed for each feature exposed by the applications.
I’ve worked on projects that use this pattern, and if you’re only focusing on your applications, it is, for the most part, fine, but it is a disaster overall. I once worked where the entire solution was protected by a proxy that did both AuthZ and AuthN. Every time we had new services or new endpoints, some code in the proxy had to change. To do so, we had to request a change from the people managing the proxy, which could take a week or more (depending on how loud we shouted). We could make changes and deliver them to the customer, but when they tried the features out, they told us that they got some error. This was in a distributed monolith where HTTP calls bounced between applications, so the error could be anywhere. We obviously started by asking the proxy team, but they asked us to register a ticket (and wait a week). We obviously spent time churning through logs on our end in case the error was somewhere in our applications. In fact, it would be better if the error was in our application because then we could respond faster. Unfortunately, the proxy was often the culprit, and when we finally got a reply, we had to issue a new ticket to resolve the problem (which meant at least an additional week).
At this point, some might be thinking that this was a problem with our proxy team and that it would never happen to them, but that is simply not the case. The issue is that the proxy becomes too important. It becomes too big to fail and a single catastrophic point of failure. Any change to the proxy is a considerable risk, as even a few seconds of downtime would lead to hundreds of thousands of calls failing and basically taking the entire solution with it.
Another issue with the proxy pattern is that it cannot actually do AuthZ without giving it even more power. Consider our example where Service A have to talk to Service B. The call goes directly from Service A to Service B, and there’s no AuthZ happening between them. This means that all these relationships between the applications must also be coded into the proxy. Alternatively, Service A has to call Service B through the proxy itself. If we do the latter and the proxy goes down, we will also crash any ongoing processes within our network. Not only are we crashing the outside world’s connection to our systems, but we’re also crashing our own connection to our systems.
To top it all off: The proxy pattern can’t safely secure the system anyway! Let’s say that all of our services are REST services that serve data over HTTP. All HTTP calls go through the proxy between the internal network and the rest of the world. Sounds secure, right? Right…? No, absolutely not. If someone connects somewhere behind the proxy, they have free reign in the entire solution. There are no checks, so anyone within the network can gobble up all the information they need.
Never. Use. The. Proxy. Pattern.
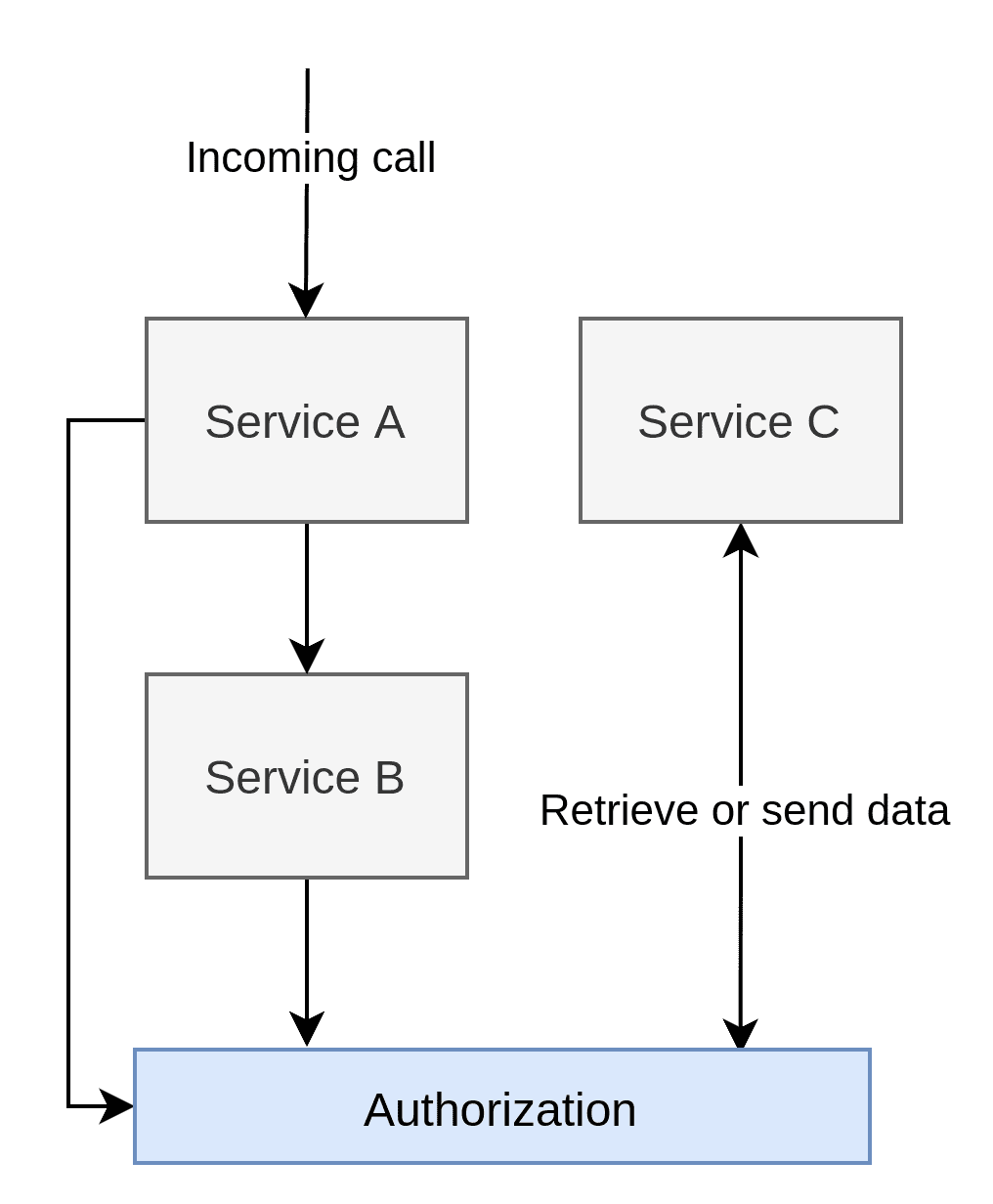
The Global Authorization Service Pattern takes the centralisation of the proxy pattern but removes the “safe zone” aspect to it. This approach is at least safer.
With the Global Authorization Service Pattern, we get all the benefits as we do with the proxy pattern, like centralisation, making it easy to make global changes, reporting, etc. At the same time, we get many of the downsides as well:
Another downside to having a single global service is that now every application will require a call to the AuthZ service, be it through HTTP or some other protocol. If we look back at our list “Fallacies of distributed computing,” we see that we run headfirst into number 2: “Latency is zero”. The fact is, latency is never zero. With a global service, there will be a lot of time spent doing AuthZ. Maybe not crippling in some solutions, but distributed monoliths are not an uncommon architecture, which means there will be many bouncing HTTP calls. In a distributed monolith, we will essentially double the number of calls necessary before some operation is complete.
A factor to consider is that having a global AuthZ service adds architectural complexity. Remember that we need data from Service C to determine whether someone is authorised, and this data needs to be retrieved in some way. There are multiple ways to solve this, but the worst would be to just call Service C from the AuthZ service. We have already doubled the number of calls necessary, and now we tripled it by adding another. We can obviously do some cache magic, but that is a temporary solution at best. A more sensible approach would embrace eventual consistency and use something like Kafka or MQ to send the data to the AuthZ service. That way, we break up dependencies, but it still adds complexity as we have to move the data from Service C to the global AuthZ server regardless of how it is achieved.
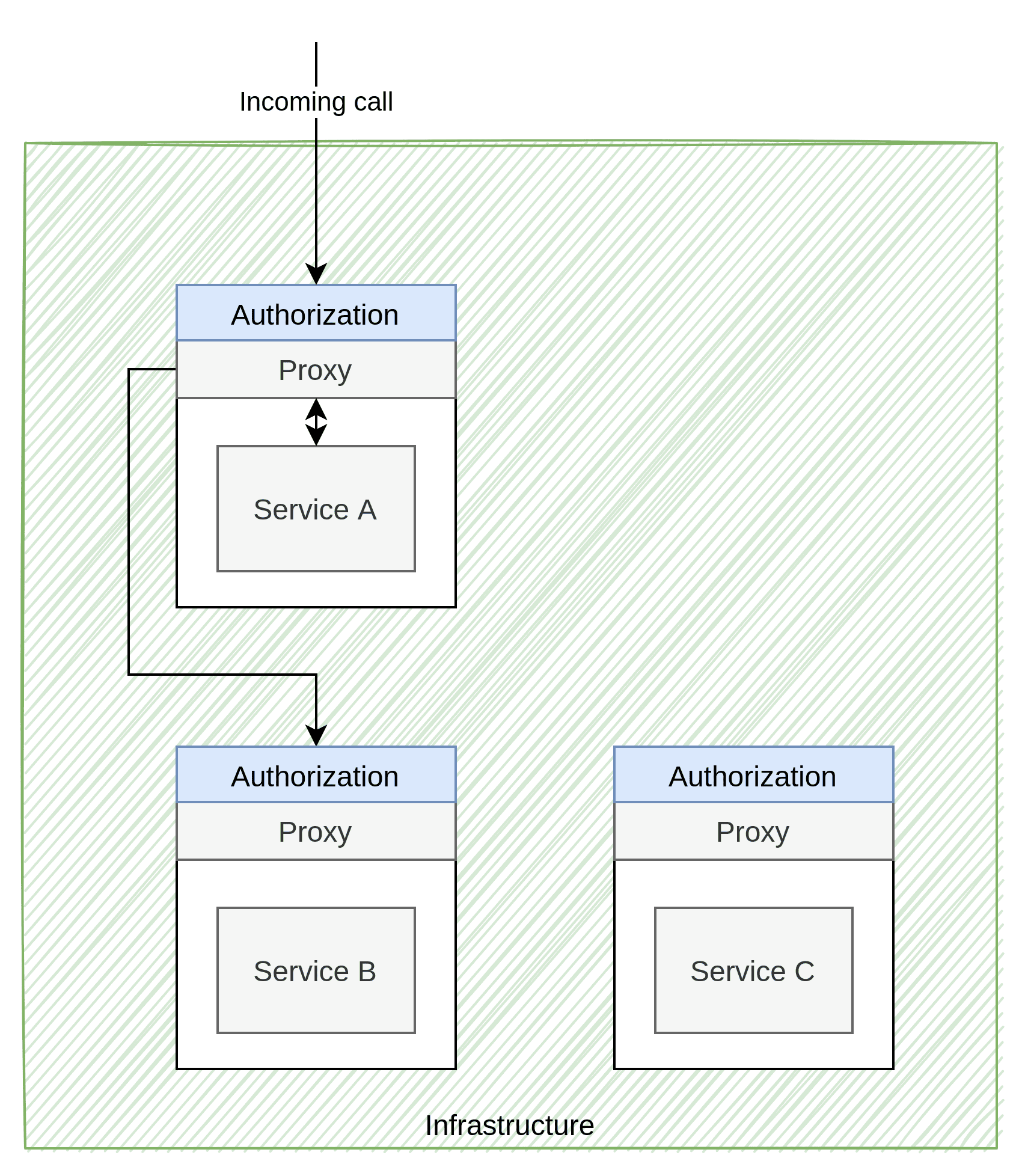
The Infrastructure-Aware Policy Pattern is somewhat difficult to describe due to how different vendors does things. AWS, Azure and Google cloud have their own ways to represent and implement policies. Service meshes such as Istio, Linkerd and Consul also have their own implementations. As such, this section will be a general view of the pattern rather than a discussion on each implementation in particular.
The image above is not necessarily how every implementation would do it either. Still, it is often done in a service mesh and can technically be reproduced outside public cloud or services meshes. It essentially means that every service is protected by their own private proxy that does authentication for them.
NOTE
Some would rename “Infrastructure-Aware Policy Pattern” to “Service Mesh Pattern”, because one would often use a service mesh to do achieve this pattern. Though, I feel this is not fully descriptive, as different providers and solutions might achieve similar behaviour with their own internal implementations, which might not be a service mesh.
The definition of a service mesh isn’t important to this discussion. Still, I believe that the naming should include what is unique about a pattern, and what is unique about this one is that it is a part of the infrastructure, and it is aware of that infrastructure. I feel this wording includes proprietary implementations that don’t fall under the label “service mesh” while describing the defining trait of this kind of AuthZ (even within a service mesh). A service mesh proxy can do many things, like dealing with AuthN, service discovery, error reporting, dynamic routing and so forth, but it can also do AuthZ.
AWS has their policies represented by JSON, while Consul uses HashiCorp. Istio uses YAML for its representation. Either way, we end up in a situation where the policies are defined externally to the application and closely coupled to the infrastructure. Moving from vendor A to vendor B might become more complicated as the business has tied its AuthZ to the vendor itself.
In the image above, note that Service C floats around without any arrows to it. Again, that is deliberate because providers have different ways of dealing with AuthZ when the data required exists within the applications themselves. In Istio, for example, you can use a feature called “External Authorization” that can route the AuthZ to some other source that can fetch that extra data from Service C. Other’s seem to have the idea that they can call an API within the application with a security token that will do the AuthZ. I have a hard time finding a way for custom AuthZ handling or feeding the infrastructure with decision data for some vendors. I can guess that most vendors would like their customers to build AuthZ purely based on roles or data that already exists in the incoming call rather than deep/complex hierarchies of logic. No matter how it happens, it is evident that the applications have to adhere to the platform’s requirements and not the other way around. Either the proxy has to ask the application (or some other application) to approve the call, or the policies must be written so that the platform can make sense of them, or some other requirements are forced upon the architecture/application.
The Infrastructure-Aware Policy Pattern is basically the Proxy Pattern done right. Rather than creating safe zones, it protects each service individually - not very unlike how Native Authorization Pattern and Internal Non-Native Authorization Pattern does it, but external to the application itself. The benefit is that the infrastructure can do the heavy lifting while providing a unified and well-documented approach to AuthZ. The downsides are much tighter integration with the platform/vendor.
While looking through the documentation, I’ve also observed how policies work and supported can change between versions. For example, in Istio 1.4, Istio had something called Mixer Adapters that could do AuthZ, but in 1.5, the feature was deprecated, favouring Envoy proxies that support Apigee Adapters. I’m sure this was the right move for Istio and that Apigee is the better solution overall, but it does highlight the issue of being too tightly connected to the platform. Let’s assume for the second that we had many services running. Then our platform decided to deprecate a crucial part of our solution that was proprietary to that platform. This ties our hands because we are forced to upgrade our services before the feature is deprecated. Some see this as a bigger problem than others, but the fact is that the platform will do what is best for the majority of the users, and more often than not, there will be someone in the minority.
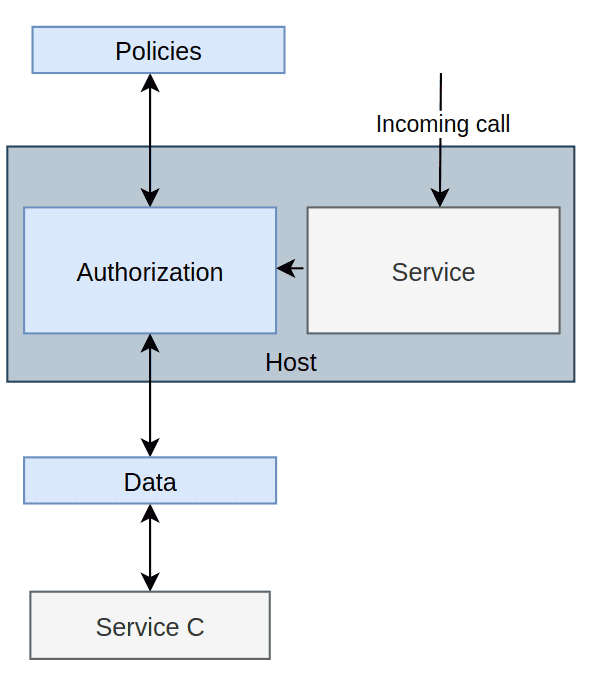
The Local Authorization Service Pattern tries to marry the benefits from the Global Authorization Service Pattern and the Local Non-Native Authorisation Pattern. Rather than having a single global AuthZ, we’re instead giving every application its own AuthZ instance.
NOTE
This pattern has also been dubbed the “Sidecar Pattern”, but I feel that it isn’t a good description of what is actually happening. This pattern can be implemented using the sidecar pattern, but all usage of sidecar patterns is related to AuthZ. If we want to name something, I believe it is better to call it something unique to AuthZ, but in the context of Azure, K8s and so forth, it would be implemented using the sidecar pattern.
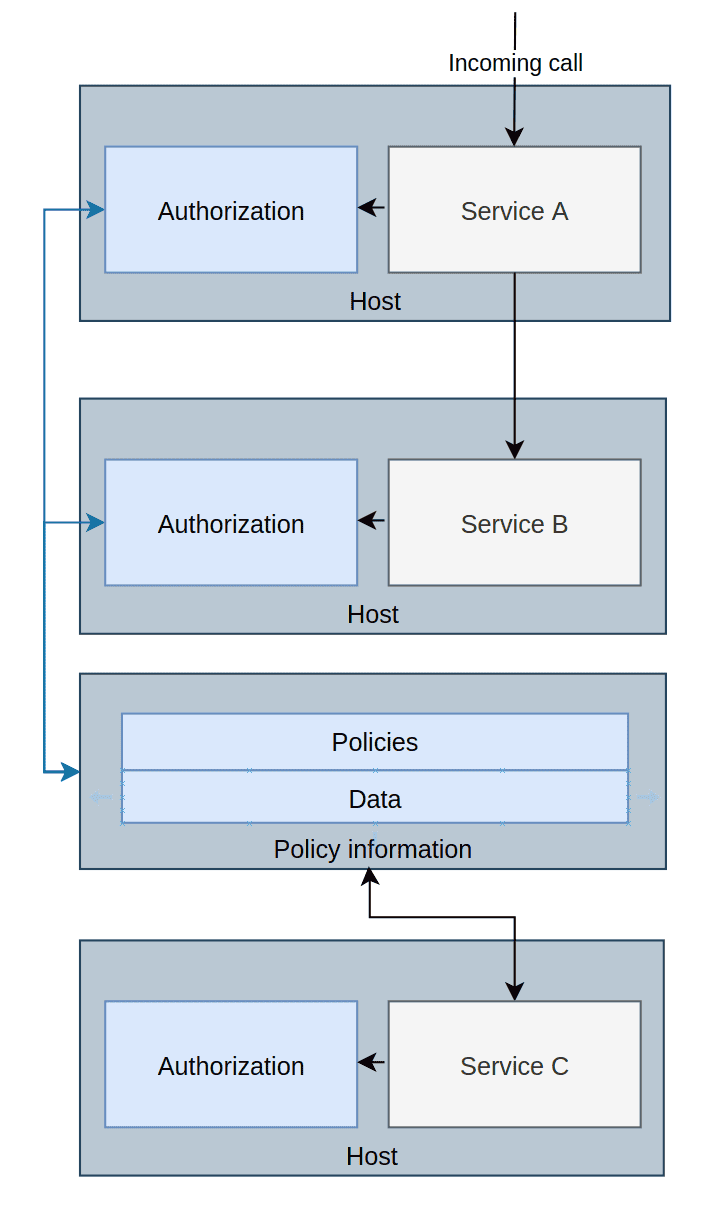
With this pattern, it is important to understand that data can both be pushed and pulled. One can set up the AuthZ service to asynchronously pull data from a service somewhere, or some application can push data to it. The same goes for policies. Everything is kept in memory, and when the AuthZ application shuts down, it is gone, but the data and policies will be re-read whenever it boots up again. This is why we get many of the same architectural complexities as Global Authorization Service Pattern, but even slightly worse, seeing that every service has its own private AuthZ service. However, we avoid a single point of failure as there’s one AuthZ service per application.
Unlike the native and local Non-Native patterns, we can make changes to policy and have them go into effect without re-deploy applications. The policies themselves can be centralised, which allows for easy global changes, reporting and documentation.
While a global AuthZ service is tough to maintain, local AuthZ service can be a little more straightforward. First of all, each team can be responsible for the policies regarding their services, as each application will have its own policy script file. A new deployment of a new ruleset is not any more dangerous than the deployment of the application itself, and there are ways to quickly test the policies separately from the application itself. On the other hand, the policies are written in a different language than the programming language. They will exist outside the application in one form or another, usually in a separate repository. The end result is that having a local AuthZ server is slightly more difficult to maintain by the team, but at least the team maintains it and can respond to errors.
While not impossible, it is slightly more challenging to test this pattern with the application itself. To the application, this is a service that could technically exist anywhere on the network. Testing the application and policies separately is relatively easy. Still, to test them together, we need to set up an environment that allows these two components to talk to each other. Making this happen isn’t that difficult in the age of containers, and Docker makes this reasonably easy. It is still a bit more effort than native and local Non-Native patterns need, as they can be verified with regular unit tests.
The biggest challenge with this pattern is the distribution of data. In our case, we need to get the information from Service C to the AuthZ services. To do that, we need to have one or more applications that can either wait for Authz services to ask for data or push it directly. They are two dangers here:
An example of a Local Authorization Service Pattern is Open Policy Agent, which uses Rego to describe policies. If we translate our account example to Rego, we end up with something like this:
package app.myapplication
default allow = false
allow {
user_is_account_owner
}
allow {
user_is_employee
user_registered_in_same_country_as_account
}
user_is_account_owner {
data.accounts[get_account_id()].owner == input.user.id
}
user_is_employee {
data.users[input.user.id].isEmployee == true
}
user_registered_in_same_country_as_account {
data.accounts[get_account_id()].country == data.users[input.user.id].country
}
get_account_id() = account_id {
some account_id
input.parsed_path = ["account", account_id]
}
Coupling isn't always a bad thing. It really comes down to where the couplings are and how they affect the overall system. Let's compare the Rego example with the Polar example from the Internal Non-Native Authorization Pattern. We see that an internal implementation has coupling between the system's internal objects, and therefore can write short and concise policies. All data sent to Rego is represented by JSON, no matter its complexities or depth. While Rego has bells and whistles to make the final policies look good, there's no denying that we are essentially dealing with JSON's Key/Value structure.
The readability of the policies themselves, if written properly, is very readable:
package app.myapplication
default allow = false
allow {
user_is_account_owner
}
allow {
user_is_employee
user_registered_in_same_country_as_account
}
However, it is only readable because I made them readable. The complexities of the user_registered_in_same_country_as_account have been abstracted away from the check itself.
In the world of AuthZ, the terms "coarse-grained" and "fine-grained" is used. They exist to describe how easy it is to filter out a call. It is not uncommon for companies to split their AuthZ implementation.
Let's say we have a Patient-service that only doctors can call. We also have the rule that doctors can only find their own patients. The company might use a centralised pattern to weed out calls that don't belong to doctors. Then a local AuthZ implementation makes sure that doctors only get to read their own patients.
I've yet to make my own mind up on whether this is a good approach. Consider the Patient-service example: If doctors can only fetch data from their own patients, then a non-doctor user shouldn't get anything anyway as they do not have any patients.
There has only been one place where I can say this approach has made sense. I once worked on a pretty large project where our customers were reasonably large organisations. The business model was to pay for the base functionality and then pay more for new features or additional functionality. Much of that functionality was always available through APIs. The only thing that stopped our customers from using them was a proxy between the customer and us.
When a customer paid for a new feature, the proxy was manually updated, and they got access. As such, mixing patterns worked perfectly fine. In hindsight, would it be better if we had a better system for knowing what features each customer had access to? I'd say so, as it was often discussions about who had access to what internally. The only way we could know was to read the proxy's source code - which we didn't have access to.
By splitting up the AuthZ implementation, you also split up the advantages and disadvantages. One can try to maximise the benefits of both, but the result will be a fragmented AuthZ implementation. The code that verifies the policies will be split across developers, repositories and languages.
As always: There's no silver-bullet solution, and the world of AuthZ is in constant change. Most of these patterns have cropped up the last few years alone, and I'm sure there are new ones on the horizon (or some that I don't know about).
There's also a lot of room for creativity in the AuthZ implementation. One idea I've personally been playing around with would be a natively generated policy file that could be used in the various patterns but also distributed to a centralised source for permanent storage. That way, we could, at any point, ask the centralised source for who had access at a particular date and time. After all, we don't necessarily just want to know what access someone has right now. Sometimes we want to know what they had access to 6 months ago. Another benefit this would provide is that it would allow the teams to own the auth code in whatever language they prefer, as long as they generate the policies in a standardised format.
The field of AuthZ is changing, so take what has been covered here with a grain of salt. The patterns are meant as a general architectural layout that one can build upon to make up for their weaknesses, not as definitive rules or targets. Either way, here's the summary for each:
Proxy Pattern:
Gloabal Authorization Service Pattern:
Infrastructure-Aware Policy Pattern:
Local Authorization Service Pattern:
Internal Non-Native Authorization Pattern:
Native Authorization Pattern:
There's no right or wrong. The decision really comes down to:
I am also optimistic about the future of AuthZ. In the last 5-6 years, we have gotten Open Policy Agent, OSO and solid vendor implementations. It is a space where a lot is happening. If I may be bold and try to predict the future, I suspect we will see policies attached to data rather than just an application's interface. In distributed computing, we know that data is flowing through systems. For example, Kafka is a system that allows data distribution without knowing who the data is distributed to. Data distribution can lead to inconsistencies in who can access what kind of data as systems can follow different policies. In an ideal implementation, the policies would be attached to the data.
For example, the information about my banking account is reasonably private and should have strict policies attached to it; even when that data is distributed within a bank's internal systems, those strict policies should apply. However, if my data is used to aggregate some statistics or to be transformed into anonymous data (for whatever purpose), then the same policies might not apply anymore.
What is important is that one goes with an AuthZ implementation being aware of and acknowledge the downsides. Suppose the business uses the Native Authorisation Pattern and one day has a breach that triggers a complete review of all policies. In that case, it should come as no surprise to anyone (not even the business) that it will be a massive undertaking. It shouldn't surprise a business if it requires massive rewrites to switch platforms if they decided to go with the Infrastructure-Aware Policy Pattern. It is all about knowing and accepting the risks and limitation that comes with each approach.
It is also critical to weigh the impact a decision will have on the developers as well. A centralised approach sounds tempting, but centralising solutions also decouple business logic from the applications themselves. This can negatively impact the teams working on said applications as they now have to consider that part of their logic lives outside the application.
All AuthZ implementations have significant drawbacks, and it is all about finding the one that fits the business' architecture and needs.

