For the longest time, my website has been hosted on Squarespace. Although I've never been particularly good at front-end development or making things look nice, Squarespace made it easy to get a decent-looking site up and running without too much fuss.
Unfortunately, Squarespace has quirks, and I have become increasingly annoyed with the platform. Therefore, I finally decided to write on my own using Gleam!
I don't want to spend too much time talking about Squarespace, as I don't find that to be very compelling. In short, it boils down to this:
Removal of features I was actively using, like embedded HTML content, which retroactively blew up one of my past posts:
No code highlighting in blog posts: 
The built-in text editor was so slow that it crashed my browser regularly for longer articles (which is why I started to write blog posts locally)
I had to manually port blog posts to Squarespace using Markdown.
Squarespace's Markdown was... quirky, so I had a bunch of Python scripts which "fixed" a lot of typical issues before manually porting them over:
There was no image support when copying Markdown, so I used Github as a CDN for images. This meant that if GitHub struggled, all the images for my site disappeared. At some point, GitHub pages were disabled on my repo due to inactivity, and the images were removed from my site without my knowledge.
There is no support for scripting unless I pay for a higher tier.
The price was too high (249 NOK, about 22$ at the time of writing). Getting the features I wanted would have increased the cost by 30%.
When making the new site, I had a few non-negotiable requirements:
Fully automated and testable from Git push to production. Full CI/CD for both the site and publishing of the articles.
Light on front-end code. I don't like HTML, CSS, or JavaScript. They don't excite me, and I want to do as little with them as possible.
Allow me to continue writing using Markdown, but with some embedded HTML if needed (and I would need to be able to port my old posts to the new site easily).
Code highlighting.
It should be cheaper than Squarespace, yet have a site that loads as fast or faster.
A "contact me" form that doesn't hand out my email to every single bot that might decide to scrape my website.
Then I had a few nice-to-haves:
I want analytics.
No cookie banner.
Avoid having a database.
Comment support.
Be portable so that I'm not dependent on a single hosting provider.
Feed support (RSS, JSON feed, Atom, etc)
I won't describe every library or technology I use in detail. See the technologies page for a complete overview.
Gleam is a new language, which runs on the remarkable Beam engine. It is fully typed and functional, has errors-as-returns, access to Erlang and Elixir's ecosystem and much more.
I could've chosen something more familiar, but what would be the fun in that? I wanted to use something new and experience how it is to make something within a smaller ecosystem with fewer resources.
Given the rise of ChatGPT and other LLM-driven chatbots, getting something up and running is easy, which I think has made people a little lazy. More important, though, is that learning is a skill that needs to be practised. Heavy use of LLMs dulls that skill, so I wanted to challenge myself with a technology that wouldn't be part of most LLM training sets—or at least that would have evolved so much since then that the data it would have had would have been practically useless.
The last reason I chose Gleam is that its creator, Louis Pilfold, genuinely seems like a nice guy. I don't know him personally, but that's the vibe I get from him, which is something I can support.
I didn't want to build a web server or a web framework. This is a simple blog; I don't want to reinvent all the wheels. Due to Gleam's limited ecosystem, the options were pretty straightforward:
Mist is a web server that allows me to do all the server stuff.
Wisp is a web framework that simplifies routing, responses, etc.
Lustre is a front-end web framework written in Gleam. It is written by Hayleigh Thompson, which I know very little about, but she has really taken to Gleam and has contributed massively to the Gleam ecosystem. It is only fitting that she is recognised for her effort here.
Now, Hayleigh isn't the reason I picked Lustre. I picked Lustre simply because I don't like HTML (We'll get into how Lustre works later).
If you ask me to centre a div, I'll run to Google and try N different things until it works on a single browser. CSS has never clicked for me, and I need all the help I can get to make stuff look nice. That's where TailwindCSS comes in.
Fly has long been active within the Beam ecosystem and was an early supporter of Gleam.
I'm uncomfortable with the idea that Microsoft, Google, and Amazon control the "public cloud." Instead, we should support smaller vendors like Fly, Vercel, Heroku, etc., which will most likely lead to a healthier web.
Fly supports containers, and I wanted to make my site container-based—it's as simple as that. This is just a tiny blog; I'm sure any cloud provider could host it.
So, I made all these decisions and considerations. How did it go?
The first thing I had to figure out was Gleam. Guess what? It's pretty nice. The slogan on Gleam's website says the following:
Gleam is a friendly language for building type-safe systems that scale!
I can't speak for the "scale" part, and luckily, I won't have to, but I can certainly say that the language does feel friendly. I have done some Erlang and Elixir, which have a learning curve. Gleam, on the other hand, is both familiar, small and straightforward.
Getting Wisp up and running was pretty easy:
pub fn main() {
wisp.configure_logger()
//More stuff...
let handler = router.handle_request(_, ctx)
let assert Ok(_) =
wisp_mist.handler(handler, secret_key_base)
|> mist.new
|> mist.port(8000)
|> mist.bind("0.0.0.0")
|> mist.start_http
process.sleep_forever()
}
Note
For brevity's sake, I'm simplifying some of the code I'll be showing throughout.
Handling routes is straightforward as well:
fn route_request(req: Request, ctx: Context) -> Response {
case wisp.path_segments(req) {
[] | ["home"] -> index(ctx)
["blog", blog_id] -> blog_entry(blog_id, ctx)
["blog"] -> blog(ctx)
["contact"] -> contact()
["health"] -> wisp.html_response(string_tree.new(), 200)
["technologies"] -> technologies()
["images", post_file_name, size, image_name] ->
try_load_image(post_file_name, size, image_name, ctx)
_ -> wisp.not_found()
}
}
I come from the world of Java/Kotlin with Spring Boot. Java isn't a small language, and Spring Boot isn't a tiny framework. There's so much simplicity knowledge required to be good at either. You need to know how AOP works. You need to know about the IoC container. There are many annotations - some of which are default and some that belong to Spring Boot itself (and don't get me started on Jakarta and Javax).
Given the depth needed to do things right, I would not be surprised if new developers are overwhelmed when they start with Spring Boot. They must feel lost for a long time (or just "embrace the magic").
Working with an explicit system, like Gleam and Wisp, feels good. Granted, some implicit knowledge is required. I need to understand OTP, Gleam's error handling and so forth. The point is that the entry barrier is much lower despite a smaller ecosystem and fewer resources.
One thing I rarely do when I work with languages like Java or Kotlin is look at the source code for the library or framework I use. I always go to the documentation or code examples. I can't say the exact reason, but with Gleam, I found myself just reading the source code to understand how to use something. It could be because some documentation could be better, but also because Gleam code is pretty easy to read.
Regarding blog posts, there were a few challenges:
I wanted to write them in Markdown.
I want to be able to schedule their publishing.
I must be able to store some metadata for each blog post.
The URLs from Squarespace should remain the same for the new site.
I need to migrate all the previous posts.
The first challenge I tackled was the Markdown challenge. The project would have died upon arrival if this hadn't been fixed.
My Markdown files have a few non-standard things that I need an HTML renderer to handle:
Generate table of contents.
Generate headings with IDs (so that they can be used in a ToC)
Friendly with embedded HTML (primarily for backwards compatibility)
Add classes to code blocks which would play well with code-highlighting libraries such as Prism.
Luckily, Marked does a lot of this. At some point I might write my own Markdown-to-HTML renderer that does exactly what I want, but this is, for now, good enough. Marked also has extensions that adds a lot of the required features (but not all...).
All of this is executed as part of a multi-stage dockerfile:
FROM node:16-alpine AS convert-stage
RUN apk add --no-cache make g++ python3
RUN npm install -g marked
COPY . /src/
WORKDIR /src
RUN make convert-blog-entries-to-html
FROM ghcr.io/gleam-lang/gleam:v1.6.3-erlang-alpine
COPY . /build/
RUN cd /build \
&& gleam export erlang-shipment \
&& mv build/erlang-shipment /app \
&& rm -r /build
COPY ./blog_entries/index.json /app/blog_entries/index.json
COPY --from=convert-stage /src/blog_entries/generated /app/blog_entries/generated
EXPOSE 8000
WORKDIR /app
ENTRYPOINT ["/app/entrypoint.sh"]
CMD ["run"]
At some point I might write my own converter, or I might contribute to the library that already exists. I'd like to do the conversion on-the-fly rather than having it as a build step, but for now it'll do.
After the above I was left with these 3 challenges left:
I want to be able to schedule their publishing
I must be able to store some metadata for each blog post
The URLs from Squarespace should remain the same for the new site
Luckily, the same system solves all 3: a JSON file.
[
{
"title": "Modern testing - Test more and better with less friction (Talk @ JavaZone 2024)",
"id": "modern-testing-test-more-and-better-with-less-friction-talk-javazone-2024",
"file_name": "modern_testing",
"publish_date_time": "2024-09-06T00:00",
"image_name": "header.png",
"blurb": "Test more and better with less friction is a talk I did @ JavaZone 2024, all about reducing friction in our automated tests."
}
//... More posts ...
]
id allows me to specify the URL, which allows me to specify the one from Squarespace.
publish_date_time allows me to set a future date and time, and all I need to do is to not expose future dates. It also allows me to sort articles.
This JSON also helps me display content where I might not want to load the entire article. For example, I don't want to read through a bunch of HTML files to find the header for each just to display the latest on the frontpage.
It might not be fancy, but it gets the job done.
One concern I had was disk I/O operations. With the setup above I had, essentially, locked myself into reading files from disk. This website doesn't really have much load, but I'd like for it to handle some load regardless.
The solution I came up with was fairly uncontroversial: Caching. After all, I don't have that many posts, and keeping them in-memory is a non-issue.
How do we make a quick and dirty cache in Gleam? After all, Gleam is an immutable language, which creates some interesting challenges. In Java I'd just create a static Map or use Spring Boot's own cache. In Gleam I can't simply "add" something to a Dictionary (Map) - because it is immutable.
This is where actors help us! Beam is great with concurrency. Some would even argue that it is unmatched in that regard. It can spin up millions of threads with ease, and these threds communicate using messages. This is also how we can "mutate" state in a running application:
pub type BlogEntryCacheMessage {
PutBlogEntry(blog_entry_id: String, blog_entry_content: String)
GetBlogEntries(reply_with: Subject(Dict(String, String)))
}
pub fn new() -> Result(Subject(BlogEntryCacheMessage), actor.StartError) {
actor.start(dict.new(), handle_message)
}
pub fn get_cached_blog_entry(
blog_entry_id: String,
actor: Subject(BlogEntryCacheMessage),
) -> Result(String, Nil) {
process.call(actor, GetBlogEntries, 10) |> dict.get(blog_entry_id)
}
pub fn put_blog_entry(
blog_entry_content: String,
blog_entry_id: String,
actor: Subject(BlogEntryCacheMessage),
) -> String {
process.send(actor, PutBlogEntry(blog_entry_id, blog_entry_content))
blog_entry_content
}
fn handle_message(
message: BlogEntryCacheMessage,
blog_entries: Dict(String, String),
) -> actor.Next(BlogEntryCacheMessage, Dict(String, String)) {
case message {
GetBlogEntries(actor) -> {
process.send(actor, blog_entries)
actor.continue(blog_entries)
}
PutBlogEntry(blog_entry_id, blog_entry) -> {
blog_entries |> dict.insert(blog_entry_id, blog_entry) |> actor.continue
}
}
}
When the system starts up it calls the new() functions. This spawns a new process which sits and waits for a BlogEntryCacheMessage. Before we read a blog post from disk, we first check whether it is cached by calling get_cached_blog_entry. If it returnes none, then the blog post is read from the HTML, and the content is stored in the cache.
This ensures that we only read a post once. There has been scenarios where larger orgs have discovered my articles and shared it internally, which in turns have resulted in a traffic spike for a single post. Now we will only do a single disk read when such spikes occur.
The website uses caches for a few things:
Store content for blog posts.
Store the data from the JSON files that has the information about what blog posts that are available and so forth.
Store dynamically resized images (Yes, I use [responsive images](Responsive images - HTML: HyperText Markup Language | MDN) to have the browser pick the best resolution and transfer as little data as possible).
The good ting here is that things only changes when there's a new blog post - which means a new deployment. Therefore there's no need to worry about caches being outdated.
Let's look at the response times:
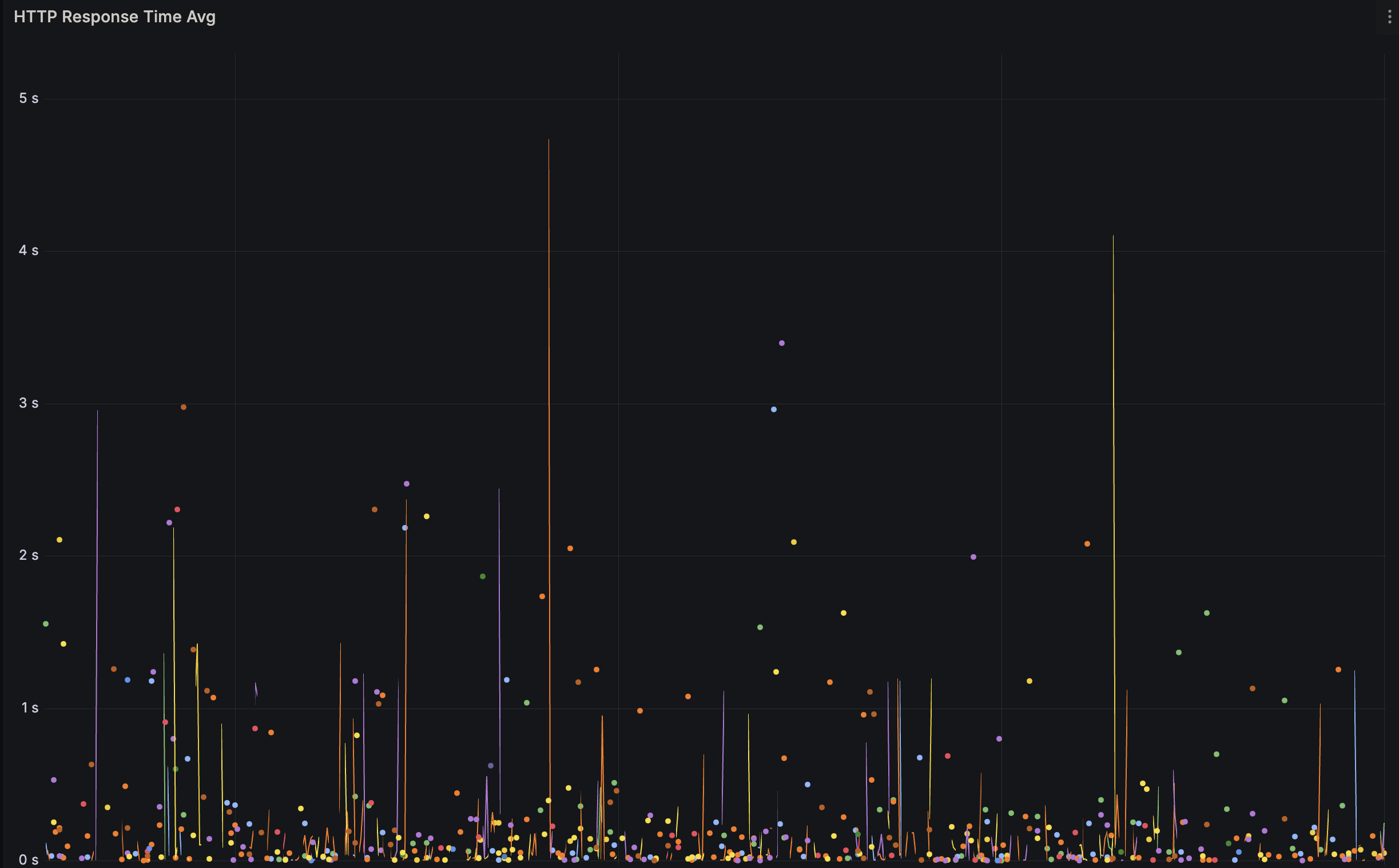
We see that tehre are some calls that can take 0.5 seconds and, at the peak, almost take 5 seconds. The vast majority of responses takes less than 100ms - which is great.
I believe a lot of the peaks are from services waking up or starting.
Not all instances of the services boots up after a deployment. In fact, most just lay idle. This means that the first call the service gets has to also boot the service - and I believe this is happening during some of these peaks.
Once the service hasn't had traffic for some time it'll go into a hibernated state. Waking up from hibernation is much faster than from a cold boot, but there's still some time needed regardless. I believe this accounts for most of the request between the 0.5 second and 3 seconds range.
Overall I'm very happy with the performance. I will most likely dig deeper into what is going, as I'd love to have sub 1 second response time for all request, but it's a good starting point.
The current page loads in transferres 619kB on the main page, which is pretty alright. I have a lot I can cut down, like using modern image formats, minimize scripts and so forth. There are definitely improvements to be made.
Where things are hosted is also important for responsiveness, so I've scaled the website to run from 12 different locations around the world. Everywhere from India, South Africa, USA, Sweden to Australia. The hope is to be decently close to most people.
The system uses an average of 122mb, which is a lot considering its just a blog. Had this been written in Go, Rust or any native language we'd probably be under a 100.
I'm more familiar with Java and Spring Boot, which easily hovers around 200-500 just starting up.
I'm also caching both images and articles in-memory, which most likely adds a good handful of megabytes.
Overall, not bad, not great. Could most likely improve it, but it is well below the smallest machine available on fly, so I won't fret to much over it.
Deployment is fully automated with GitHub Actions:
- uses: superfly/flyctl-actions/setup-flyctl@master
- run: flyctl deploy --remote-only
env:
FLY_API_TOKEN: ${{ secrets.FLY_API_TOKEN }}
There's a lot more going on in the CI/CD script as well:
It create sa GitHub release.
It creates an image which is stored on GitHub's conainer registry.
It runs smoke tests to verify that the service can run and responds correctly.
It runs normal unit and integration tests.
The second some change is pushed to the main branch it'll be picked up and automatically pushed towards production.
There was two things that really bothered me with Squarespace. One being functionality, and the other being cost. I've had the site running on Fly for a month now, so what was the monthly cost?
To quote the email about billing from Fly:
Good news from Fly.io! We don’t collect bills smaller than $5.00 on your default (personal) organization.
This month, your bill of $2.92 falls below that threshold, so we’re discounting it by 100%.
This includes around 50 deployments, which also comes with some cost.
Am I happy with this result? Absolutely! Why wouldn't I be? When starting this project I wasn't aware of Fly not collecting anything under 5 dollars, so it is a pleasant surprise to say the least.
One thing it demonstrates is that this website isn't the center of the universe. It has limited reach, which is fine. But that also strengthens the argument against Squaespace's price.
| Technology | Use-case | Comment |
|---|---|---|
| SimpleAnalytics | Analytics | Grants me some analytics without needing a cookie banner. |
| PrismJS | Code highlighting | Allows me to have code blocks with actual highlighting. |
| Web3Forms | Contact me | A simple "contact me" form so that I don't have to build anything on the backend and deal with emails. |
| TailwindCSS | Styling | I've always been awful with CSS and TailwindCSS really made my life easier. |
I won't be able to import my comments from Squarespace. It's a shame as there were a handful of comments I'd love to bring over. Unfortunately, that won't happen.
The main issue is that I really do not want a database, nor do I want to deal with implementing anti-spam functionality or administration functionality. I'm also cheap, so I don't want to pay for it if I can avoid it.
There are alternatives, like using someting like Giscus which bases itself on GitHub Discussions, but that feels a tad hacky.
Comments are, luckily, not a core feature, so I'm okay with its absence.
Some might wonder why I used Marked versus something available on Beam. Actually, there is a project that converts Markdown to HTML written in pure Gleam: kirala_bbmarkdown. The only issue is that it had some... quirks:

It also lacks a lot of the features I need. I would therefore be forced to implement a lot myself, which I found to be out of scope for V1.
At some point I might either contribute to bbmarkdown or build my own implementation where I can take the Markdown files and convert them to HTML on the fly - or maybe even convert it to Lustre!
There might be something else in Erlang or Elixir which I haven't explored that I migth be able to use as well.
My overall experience has been great! Gleam has been a pleasant language, and its ecosystem has offered most things I need. While there has been some challenges due to lacking documentation I've still managed to get things to working with relative ease.
All technologies involved has been great! If you have the opportunity I recommend you head over and support the creators by either using their stuff or by donating!

