Patterns of Narrow Integration Testing
Content
- What is an integration test?
- Narrow vs Broad
- Database
- Files
- RabbitMQ/Kafka
- Web APIs
- My type of dependency isn’t here, John! What do I do?! (Generic patterns)
- Conclusions
- Broad: Where you spin up live versions of all services and run tests against them. Broad tests need substantial setup and maintenance to maintain and is often conducted in a staging environment where all systems run.
- Narrow: Where you test an individual service but mocks most of its external dependencies.
- Broad integration tests are slow: Since broad integration tests have to run live versions of all systems and bounce data between them, the tests are naturally slowed. It is not helped that we need to make sure to run the correct version of various services as well as setting up all of them with different data.
- Broad integration tests are complicated: As explained, a lot is going on in these tests so that they can become complicated very quickly.
- Board integration tests are hard to maintain: We quickly run into similar issues as we do with E2E tests, that we must limit the number of tests because, if you have too many, it can become a nightmare to maintain.
- Narrow integration tests are fast: While not as fast as unit tests they run with such a speed that they can be executed during compile time on the developer computer. That means faster feedback for the developer.
- Narrow integration tests are more straightforward than their broad counterpart: They require less setup as they only need to worry about the design of mocks and maybe a database.
- Narrow integration tests are easier to maintain: Which means we can have a bunch of them!
- Broad integration tests try to verify the correctness over how one service interprets another service’s contract.
- Narrow integration tests assume that the contract is correct and has more tests for how a single system interacts with that contract.
- Broad integration tests verify the contract
- Narrow integration tests verify the interactions with the contract
- External web APIs
- Database
- Files
- Messaging systems/queues
- Searching systems
- Run locally on a developer’s machine (no need for an external environment)
- Require no external configuration
- Run as part of the build per default, but can be manually excluded
What is an integration test?
Definitions are hard. It would be so much easier to write something if I could rely on the reader just knowing something. I.e. what an integration test is. The issue is that I’ve seen many developers confuse integration tests with unit tests (because they were written in the form of a unit test), and I’ve seen high-level system tests been mistaken for integration tests but weren’t. Therefore, it is clear that before we do anything else, we must first define what an integration test is.Wikipedia states the following:
“Integration testing (sometimes called integration and testing, abbreviated I&T) is the phase in software testing in which individual software modules are combined and tested as a group.”
I’m not too fond of this definition, because it implies that tests which mock dependencies to other systems are not integration tests, as that is not combining the systems as a group.
Guru99 has a similar issue with its definition:
“INTEGRATION TESTING is defined as a type of testing where software modules are integrated logically and tested as a group.”
The third result on google is an article by Martin Fowler where he brings the problem of defining integration tests, and he arrived at a conclusion which I agree with, that integration testing is a polysemy.
Narrow vs Broad
The essence of integration testing is to figure out that things are talking to each other correctly. We want to verify that the service contract is adhered to, but also interpreted correctly.I recommend reading Martin Fowler's post as it goes more into detail about the differences between the two types of integration testing than I will here. Summarized we have two levels of integration testing:
Commonly, the broad integration tests are on a very high level written as black box styled tests. They trace the effects of a call throughout the overall solution to figure out that everything is talking together correctly. In the broad category, we are running entire databases with real services which transfer data to each other.
Why do we need narrow integration tests?
Narrow integration tests can seem a bit superfluous compared to broad integration tests. After all, don’t broad integration tests already test the communication between the various systems in the solutions? The answer is yes. If the goal is to verify that something is communicating correctly, it is better to test the actual systems running live and not mock the services. Note that this does not take away from narrow integration tests.To determine the value of narrow integration tests, we must see where its broad counterpart falls short.
In comparison, narrow integration tests make up for the shortcomings of broad integration tests:
Like many things in software development, a practice cannot be determined in a vacuum, as techniques often make up for the downsides of other techniques. We see this happening with companies which only want to adopt parts of agile. They don’t get the full benefit because they implement just the parts they deem necessary without realizing that everything builds on something else. It is the same with narrow and broad integration tests.
To have a healthy test portfolio, we should have both broad and narrow integration tests, but their goals are slightly different:
To distil the differences in the goal of narrow and broad integration tests even further, we can say that:
Does broad integration tests verify the contract by having systems interact with it? Definitely, but it is not as detailed as with the narrow integration tests. The question is not necessarily whether or not the systems did the right thing; rather, it is whether or not the information was transferred and interpreted correctly.
Narrow integration tests and you
Now that we have successfully managed to define what an integration test is, we can start talking about how even to write tests for our application. As the title of this post indicates, we will only focus on narrow integration tests and leave broad integration tests for another day.Narrow integration tests can be viewed as I/O tests for our application, often written in the style of unit tests. So let’s define the most common I/O our systems tend to have:
When we write narrow integration tests, we don’t usually want to test the input of our application. Our system’s input will be covered and defined by automated high-level functional tests and automated acceptance tests. Broad integration tests will also touch it. We are potentially looking at a bunch of duplicated tests, so we usually don’t want to write narrow integration tests for the input of our system and instead focus on data which our system requests.
Now that we know what we are supposed to test, we should then look at the rules our narrow integration tests should adhere to. A narrow integration test should:
What does a narrow integration test actually look like?
A narrow integration test has the shape and form similar to a unit test, but it also has to deal with the service’s I/O in some way. Narrow integration tests use the standard unit test framework and are indistinguishable from regular unit tests except that it often requires a bit more set up to deal with whatever dependency that is used.As with unit tests we often have one test class per class in our production code with a bunch of tests and the same goes for narrow integration tests, and we have the same for our narrow integration tests. Consider this class from the spring boots guides:
@SpringBootApplication
public class ConsumingRestApplication {
private static final Logger log = LoggerFactory.getLogger(ConsumingRestApplication.class);
public static void main(String[] args) {
SpringApplication.run(ConsumingRestApplication.class, args);
}
@Bean
public RestTemplate restTemplate(RestTemplateBuilder builder) {
return builder.build();
}
@Bean
public CommandLineRunner run(RestTemplate restTemplate) throws Exception {
return args -> {
Quote quote = restTemplate.getForObject(
"URL_TO_RANDOM_QUOTE_API", Quote.class);
log.info(quote.toString());
};
}
}This might be a very simplistic example, but a narrow integration test for this code would be to verify the call to a random quote API.
In short, narrow integration tests are unit tests for the I/O, but they are distinguishable from unit tests because they deal with I/O. We should not make the mistake of calling narrow integration tests for unit tests even if they are written as such.
If the definition of a unit test is a test which tests a single aspect of the code, then the definition of a narrow integration test is a test which tests a single aspect of the code that interfaces with I/O in some way.
Database
Maybe the most common component which one must figure out how to integration test must be the database. The good thing about databases is that they are very self-contained - they don’t rely on anything else. There are two ways of reliably do this:- Mock the outer layer, whatever DB framework that is used. I.e. the repository/query object which your DAO/repository uses to access the data.
- Use an actual database and fetch real data.
Mock the repository/query objects
This is my least favourite way of dealing with database dependencies, but it is a valid one considering that the wide integration tests will cover the actual database interaction. In this scenario, we pretend that the database exists by using a standard mocking framework (Mockito, etc.) and replace the DB/ORM layer entirely.The main benefit of this is that we don’t need a database running and our tests will be blazing fasts.
Running an actual database
Database migrations should be easy to replicate, as I have previously stated in my post about database migrations. That means that we should be able to automate this process, even on a local database.By running a local database, it might seem that we are breaking our “no external dependencies” rule. I view it as we are bending the rules a little. Some might argue that we are trespassing on the territory of wide integration tests, but I disagree. We are limited to how many wide integration tests we can have without feeling pain, so we should limit them wherever possible, and doing database tests as narrow integration tests makes much more sense. There are two main reasons why I think that:
- A service might have a bunch of different tables, all with their DAOs/repositories which must be tested. Having all these tests in the wide integration test might not be feasible, yet we want to test them all.
- A database is very much an independent piece. If you need other dependencies to spin up a database instance, then you are probably doing something wrong.
This approach is, to me, last resort, when there’s absolutely no other way of running a database. The reason for this is that this way of testing doesn’t make sure that the database understands our objects/data structure and vice versa. We never get to test that conversion. Even if we found some mocking system to throw around the ORM/Database framework, we still cannot be sure that the actual database will understand.
When we’re running tests towards an actual database, we must do a few things as part of the setup for our test:
- Spin up our database in some way
- Migrate the database schema
- Insert whatever required data one needs for the specific test.
Using an in-memory replacement
There’s no lack of in-memory databases on the market, and the most well known might be SQLite. Using an in-memory database allows for quick start and teardown, which is excellent for our tests. Spring, for example, will spin up an h2 database as default.If we use a database framework which allows us to switch out our database provider at will, and our schema is so generic that it can be transferred from one SQL based to another, then this can be a practical way. We might be other types of databases, like NoSQL, distributed and so forth. There might not be possible to switch over to a different kind of database provider that is used in production, or there might not be an easy way to spin up your database locally.
What is so great about these in-memory databases is that we can spin one up without requiring any external dependencies (like docker) to make things work.
Using docker
Most database servers have their docker instance at docker hub. We have MySQL, MongoDB, progress, etc. are all on the docker hub. If that is not what is required, it is pretty easy to make your docker image which can be uploaded to whatever preferred image repository. Therefore, the first step will be to either find an official (or official enough) docker image or make your own.The second step is to include this in your build tool. Whether it is Maven or MSBuild, most have dependencies which can interface with Docker and automatically start various containers. Or you can have a docker-compose file which gets executed before the build taking place. The point is that we’re spoiled for choice and there are multiple ways on how we can achieve spin up a new database instance on the fly.
While docker makes it easy to spin up databases of all kinds, it also comes with some quirks. For example whenever I run up a container with Oracle SQL, then docker returns successfully before the Oracle SQL server is ready. This means that if I continue with the build, then it may fail because the SQL server is still working on setting itself up. The workaround so far has been to add a hardcoded timeout to the setup, but that is not very elegant. If there isn’t much proprietary trickery in the schema, it might be well worth switching to a lighter database system for these tests, like SQLite. It might not be possible, but it is something to consider. We want our integration tests to be as fast as possible, and the more we have to wait for the tests to complete the less value they bring. The actual integration will be indirectly verified by the wide integration tests anyway, so it isn’t vital that we are using the same database for the narrow integration test.
Files
Some view batch systems as an outdated practise which has been replaced by messaging brokers, such as RabbitMQ and Kafka. While I can see the reasoning for that, there is no denying that batch jobs exist and file generation is still very much a thing. Another thing to consider is that the file system is a dependency our application has. Depending on the language and framework used, it might almost be abstracted away at this point, but it is still there. This means that the structure of our files, both read and written, is a contract which we must verify.Writing files
Some jobs are, inherently, batch-based. Banks might want a report generated once a day in the form of an XML file (or CSV, ugh). Some governmental systems require a yearly report generated in a specific format and so forth. While the basis of this data might come from a broker of some sort, there are still business requirements which dictate that we generate specific types of files at particular times, so batch applications and file transfers will continue to be a thing for the foreseeable future.Writing these tests is pretty straight forward:
- Have a dataset ready
- Generate file
- Compare the file to another hardcoded file which has already been verified to be correct
When generating a file, I’d like to suggest that we don’t write it to disk. I am much more in favour of wrapping the actual functional call, which writes a file to the disk, in a class and an interface:
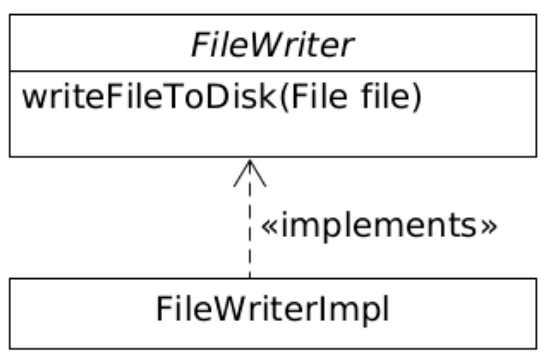
In the model above, we see that we have wrapped the actual I/O call in a class. It is the last chain of our call, but we can intercept it as a mocked object. That means we can get direct access to the content of the file and all other parameters without writing anything to disk.
There are multiple reasons why we might avoid writing a file to disk:
- Writing a file to disk adds a file to the file system which needs to be cleaned up and dealt with somehow. Suddenly there’s a new file in the git commit, or you have to take other precautions to make sure that such files don’t cause a mess. It is another thing to consider.
- In most high-level languages, file reading and writing files has become a non-issue. If we have managed to create the file object, then we are pretty much guaranteed to be able to write the actual file to disk. We are running this test locally on our machine; thus we won’t be able to test whether we have the correct paths anyway, so we might as well not write to disk. What is essential is that our code thinks it has written a file to disk.
No matter whether the file is written to disk or caught by a mock, we the next step in the process remains the same: Read the content of the file. It might be tempting to parse the content into some object structure, but I’d recommend against it—the more logic put into our tests, the more problems we create for ourselves. Instead, we should have a hard-coded file which our generated file should be equal to. We can choose to compare the content or hash the file and compare it that way.
Making that initial hard-coded test file can be a bit of a pain. Some might see me as a heathen for saying it, but I’d recommend generating a file based on your desired test data and use that as a starting point. We cannot get away from having to check the correctness of the hard-coded file manually, but when that is done, we only need to verify the correctness of any changes made to it.
Reading files
Reading files is much easier than writing files. It doesn’t cause any external artifacts, and we don’t need to put in much effort to fake the environment the code runs in. To test an incoming file, we only need to:- Read a hard-coded file
- Compare the result of the read (usually an object of sort) with whatever hard-coded result we might have in our test (like a normal unit test)
RabbitMQ/Kafka
Message brokers are popular these days and have become a vital cog in micro-service architecture, and therefore they should be a part of our integration tests. Message brokers are still an external dependency which requires our app to either send data in a particular structure over a specific protocol and be able to fetch data with a particular format. As with the other types of tests, the actual correctness of the contract can only be verified by the wide integration tests, but sometimes it is warranted to write narrow integration tests as well.You might get away with not having narrow integration tests for message brokers. It depends how much logic you might (or might not) have in the layer/class which deals with the message broker logic. If it is separate enough, then wide integration tests might be enough. If there is a bunch of logic which is hard to write regular unit tests for I do recommend writing narrow integration tests, but it might not always be required.
Luckily for us, it is pretty easy to write tests for either RabbitMQ, Kafka or whatever other message brokers you might be using. For RabbitMQ we can use RabbitMQ-mock and for Kafka has mocking built-in. The approach is simple: We mock our message broker in the setup of our test and simply run the test.
Web APIs
The other, maybe most common, external dependency might be other web APIs which comes in all shapes and forms. We may be dealing with SOAP, REST, GraphQL or some other technology, all of which bring their own challenges.When I say web APIs, I am primarily talking about protocols running on HTTP. We will explore other ways of transferring data later, but for now, let’s keep the conversation to HTTP based protocols only.
The solution to all is mostly the same, however. We know that we cannot run all of these services locally as all might have other dependencies and databases which they rely on. The goal is to run something locally, which our service can connect to and return some predictable value, which we can use in our test. Currently, I’ve seen this be solved in two ways:
Make a test service
Rather than trying to run the external services locally, we can instead make a complete master service which only contains the test data. It duplicates all the contracts from the other services but returns the same data every time. This means that we can use the test service as a stand-in for whatever other dependencies we might need. This test service can be reused across a whole range of services and serve as the one-stop-shop for all narrow integration tests that go towards an API. I do not recommend having its test service for each real service, as that quickly becomes messy.If we also package this test service into a docker container, we can simply add it to docker-compose and have it automatically start up during testing so that the developer doesn’t have to worry too much about it while developing.
While this approach works, it is not the one I would default to. Making a test service might be a good idea if you’re working with some proprietary technology, or any technology which doesn’t have a mock standing available, however, one should avoid this if possible as it comes with some downsides:
- To introduce variants in the response, we have to include logic in the test service
- We have to manually update the test service when we make changes to the contracts for the actual services
- By changing the data in the test service for our test, we risk accidentally breaking tests in other systems
- Gets more complicated as more endpoints/contracts are added to the test service
Mock the external servicers
The easiest way of dealing with external web services in narrow integration testing is simply to mock it. After all, the actual contract will be tested by our wide integration tests; thus, we don’t need to worry about whether or not the contract is correct at this stage.REST
The easiest way to mock REST services is to use something like MockServer. These HTTP mock servers make it easy to capture arguments as well as responding over HTTP connections. MockServer specifically can even be used as a container, basically achieving the same capabilities as your test service, but configurable on a per-test basis.GraphQL
Since GraphQL has a standardized way of dealing with requests, returning in standardized formats like JSON, we might also want to use MockServer for GraphQL, but MockServer is very basic in how it works and might quickly be too simple. A better solution might be to use the Apollo server instead. Either way, the answer is mocking.SOAP
SOAP is a fickle beast. I don’t have much against the technology itself except for its verbosity, but I despise the general environment which SOAP lives in. Pretty much all tools involved with SOAP either costs money or feel clunky to work with - it just all feels outdated. So does the default option for SOAP which is SoapUI. While historically been a desktop application, SoapUI can also be integrated with the application and run as part of your tests, and it can mock. What people seem to have done is making docker images with soapUI installed and starting the mock server that way, which is a very technology agnostic way of doing things.When working with SOAP services I have resorted to using the method where I build my master test service, but there are projects like this which seems promising which I should take a closer look at (a post for the future?).
My type of dependency isn’t here, John! What do I do?! (Generic patterns)
Writing narrow integration tests isn’t magic, and it is all about sensing outgoing and incoming data, as well as being able to send and respond to requests. If we can do these things, we can write narrow integration tests. The whole idea is to be able to contain the application in a test harness. That way, we can write these narrow integration tests, but we can also run our system locally without any dependencies to any external environment. That means that manual testing will also be more manageable.The points above don’t capture all protocols, applications or ways of transferring data. So this section will be a general catch-all for whatever I haven’t concretely covered in the rest of this post, but we will see an available pattern on how to approach a given dependency and the solution.
Note that I am not saying that one solution is better than the other. It all depends on the context. For some dependencies, like the database, it is easier to just run the dependency rather than trying to fake it. For other dependencies, like SOAP, it might be easier to do a complete fake service to write tests for it meaningfully.
Mock the dependency
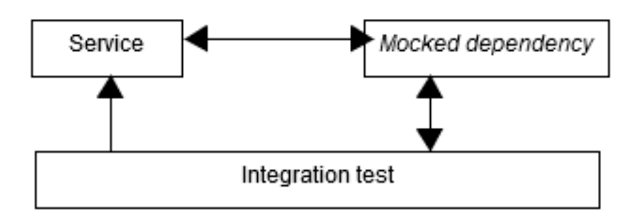
This is usually the most preferred way, as it makes life so much easier when writing the tests. It allows each test to specify the behaviour of the mock, as well as the return data. It also keeps all the test related data within the test itself. This approach tends to make the tests a bit bloated, but that is hard to avoid.
While there might not be a framework or server which is made for whatever programming language that is used, there might be a docker image which can be reused for this, so it is often worth looking around.
This system is described in the “make a test service” section in this post, but it is not limited to webs services only. Whatever that cannot be mocked easily; we can replicate with what I like to call a manual mock.
Sometimes, like in the case of SOAP, there might not be any readily available mocking tools for whatever platform you use. Or the ones that exist are so clunky that you don’t want to use them. In these situations, we might want to consider making a mock system ourselves.
Writing your manual mocks might not be worth it, and should be judged on a case-by-case basis. It is generally worth it if most of the solution relies on the technology which we are trying to mock. If it is just one dependency in the overall solution that has this problem, then it may not be worth it and instead use one of the other approaches might serve you better.
Abstract and mock the outer layer of the application
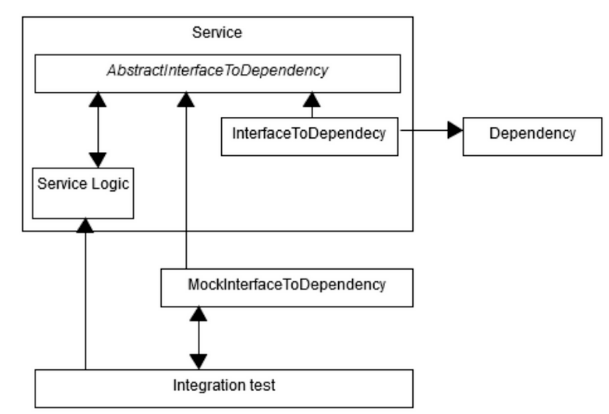
If there is no easy way to mock the dependency itself, it might be easier to simply mock the part of the code that interfaces with the dependency. In this approach, we simply extract out all the logic and hide the direct calls to the external dependency behind an interface which we can pretty quickly mock with a standard mocking framework.
The downside is that this might require rewriting parts of the service, which we usually want to avoid, but it is guaranteed to work with pretty much any modern programming language and any protocol on the virtue that we are merely ignoring the external dependency. Another downside is that we are not testing whether or not our application can communicate with that technology, but that will be caught by the wide integration tests anyway, so we shouldn’t worry too much about that.
Another thing to consider when going with this approach is whether or not we are writing integration tests at this point, and I would agree. At this point, we are writing unit tests, as we have abstracted away from any I/O dependency. This is also why we should be careful going this route as we are not testing the integration in any way. That said it is all about confidence in our application working, and if we trust our wide integration tests, this might be an appropriate solution.
Run the dependency
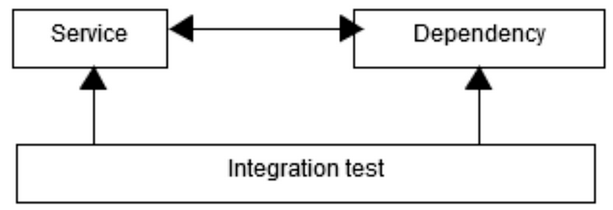
If possible, we should require as little setup as possible when writing our narrow integration tests, but sometimes it is easier to run the dependency than it is trying to fake it in some way. Technologies like Docker have made setting up reusable containers much more straightforward than it ever has.
A consideration that should be made when considering this approach is whether or not the desired test belongs as a wide integration test rather than a narrow one. We made an exception with the database previously, but that is because databases tend not to need any other dependencies and our systems tend to have a bunch of different queries which all need to be tested. There might be similar situations for other scenarios where this approach does make sense.
Conclusions
One thing that keeps disappointing me in the world of programming is people’s lack of understanding that things almost always build on each other. Integration tests are one of those things. You can have wide integration tests or big E2E tests, but they will not be able to capture the detail which narrow integration tests can. At the same time, we are limited to what we can test in our narrow integration tests, so we also need wide integration tests. Having just one category of integration testing is better than nothing, but it is nothing compared to the benefit of having both.Writing tests is hard. Not only because it is difficult to get right, but it is also something which many don’t prioritize all that much. When we add the additional dimension, which is external dependencies, we make it even more challenging to manage, so we often see bloated test environments which take hours upon hours to execute tests. Or we see such tests disabled in the pipeline entirely because people can’t be bothered with fixing them. I do think this is the wrong approach, and instead, we should work with making our tests more reliable and portable. I hope that my post has given some food for thought in that sense.
Another goal of this post was to serve as a starting point on how we write our narrow integration tests as well as documenting some of the patterns I tend to use. Hopefully, I discover newer and better patterns as I progress as a developer.