Technical debt is a sinister issue that plagues many companies, yet many of us are happy to ignore it. So many developers and managers are happy to prioritise other things over technical debt and allow our codebase to rot.
Let's look into the nature of technical debt, what makes it so dangerous and how it can kill companies.
Throughout this post, I'll use the word "debt" quite a lot - to the point that it might lose all meaning. It is important to understand that "technical debt" is a metaphor; almost all metaphors can only go so far. It is easy to be consumed by the metaphor and loose picture of what we're actually talking about.
That said, for this post to make any sense, you need to know my interpretation of the term "technical debt".
Wikipedia provides us with the following definition:
In software development, technical debt is the implied cost of future reworking required when choosing an easy but limited solution instead of a better approach that could take more time.
It is an okay definition, but it is hard to really wrap your head around.
I prefer Martin Fowler's description, though he uses "cruft" over the "debt" metaphor:
Deficiencies in internal quality that make it harder than it would ideally be to modify and extend the system further.
The only thing I want to point out with this definition is that it can be interpreted that technical debt is built into the system, which isn't the case. I believe that a technical debt can be something that doesn't exist in the codebase. For example, I view outdated frameworks and libraries as a form of technical debt. Why? Because they will, over time, make it challenging to update language versions and, at some point, limit how you can modify and extend the system. Then again, one can argue that the library version is coded into the codebase, but I think we can agree that it's a grey area.
Perhaps a better example would be the lack of automated tests, which I also view as technical debt. The reason is that lacking tests means you'll have a harder time modifying and extending a system without causing undesired side effects.
We should go with Fowler's definition with the extra context that "deficiencies in internal quality" doesn't mean that the issues must be explicitly stated within the codebase.

HealthWiseIT is a fictional company that creates EMR/EHR software that primarily deals with healthcare records for smaller clinics and niche parts of the healthcare industry. Let's explore HealthWiseIT's journey through the technical debt spiral.
It starts at the top of the spiral when things are still relatively good. The codebase is largely painless, and new features are steadily added while bugs are fixed in a reasonable amount of time. Developers, managers and the business, in general, see the momentum and feel they're on the right path.
While working, the developers make decisions, which at the time seemed reasonable, but didn't fit how the solution evolved. Maybe they structured their database schema incorrectly. Maybe they used abstractions which turned out to work against them at a later point. Design decisions' appropriateness is always revealed later in the development process, and this company is no different.
After a year, the team starts feeling the restriction of their design. However, they have not developed a culture that continuously pays technical debt, and management expects the momentum of new features to remain the same. As such, technical debt is ignored in favour of new functionality. The sentence "We'll fix it later. Right now, we need to deliver this" becomes increasingly common. Regardless, the issues are not too problematic now, and most things can be worked around relatively easily. Due to this focus on delivery, HealthWiseIT quickly becomes known as the up-and-coming provider that simply "gets things done" compared to its slow and stubborn competitors.
Another year goes by. HealthWiseIT is profitable but faces fierce competition - as most industries do. Since the technical debt could be ignored, it was ignored. The team has essentially doubled down on not paying technical debt, and now the debt is starting to constrain development. Working around problems is increasingly more complex and error-prone than before. The system is now built around technical debt, so trying to fix it at this point would require a significant investment of time from the developers. The leadership is starting to see signs that the momentum is trending downward; however, they know that productivity is also expected to take a minor hit as systems grow. In their eyes, that is business as usual - At this point, they hire some additional developers to offset the lost productivity.
HealthWiseIT is now in its third year and seems relatively similar to last year. The efficiency took a hit as the new developers were trained, but once they became productive, things started settling into a decent pace. The team seems to have about the same productivity as last year. Everyone is happy. The graphs do not show that they are on the same level of productivity but now with additional developers. If they had looked at individual contributions compared to last year, they would have seen that they're still trending downwards and they're way down from the previous year. In fact, the performance loss is hidden by the new developers.
During the next couple of years, some of the key developers leave. They cite the reason to be that they want to change, but they've also grown tired of the increased complexity of maintaining the application while maintaining a certain pace to deliver new features. They see where it is heading, and they don't feel they have the support from management to implement any meaningful changes. Since key talent has left the organisation, there's a natural hit to the team's productivity, though the hit is larger than it would have been in a healthy codebase, but nobody notices. Management expects productivity to take a hit but does not know how large or small such a hit should be.
At this point, HealthWiseIT has tried to capture larger customers, like hospitals and large clinics, but they've been unable to scale their solution in any meaningful capacity. HealthWiseIT have been able to improve the performance of it systems, but those improvements primarily manifest as workarounds of the core system itself. Fixing the core issues in the systems at this point would be very time-consuming, which the management doesn't have time for.
The following year is painful for the team, and things really start grinding to a halt. If any talented developers are left, they'll most likely leave at this point. Management will become increasingly more frustrated as the effect of neglected technical debt really starts taking its toll. Due to outdated dependencies, the system cannot be updated to a newer language version, which means they're stuck on old versions unless someone spends weeks upgrading the codebase(s). The company tries to hire people, but most capable senior developers decline job offers, and management doesn't know why. Making changes to the codebase is near impossible as changes in one place completely break the other. Management is frustrated, and the team says that rewriting the entire thing is the only real solution.
We're now eight years in. Some of the talents hired last year leave this year as they realise the state of the codebase. Only a couple of people from the original team remain, if any. The ones that are left have learned to live with the codebase and have no drive to improve it. After all, the culture has never appreciated the value of paying technical debt, and management has been more than happy to push for new features. The remaining team is more than happy to perpetuate the codebase and might even resist any changes going forward. After all, this is how they've always done it.
From here, there's a downward spiral. The company cannot hire talent, because the talent realises the poor state of the codebase. The existing developers have no interest in improving the codebase, and management has been trained to value features over improvements. As a result, more technical debt is added, and development goes slower. The product itself has a ton of bugs, as every change results in something breaking.
At this point, there are likely new competitors out in the market. Their technology is modern by comparison, and they're at a stage where they can maintain momentum regardless of how good or bad their actual development practices are. Regardless, the company cannot keep up, and in the market, they're known as the old and bloated application of yesterday. Few releases with little innovations while the bugs start piling up.
Luckily, HealthWiseIT has money to burn, so they start a costly rewrite project, but they need their best people on the case to get that off the ground. Determining "the best" is always difficult, but they have a couple of senior developers who have been with the company for some time. The company started hiring for a new team headed by the senior devs. What management doesn't consider is that these senior developers allowed the codebase to become what it became. They also perpetuated and made the effects of technical debt worse.
Since the senior developers have accepted the technical debt for so long, they don't see the core problem. They see the problem as a purely technical one. In other words they see a problematic database schema. They see a rigid internal structure. They see an old language version.
They don't see the underlying issue: Not actively and continuously removing technical debt. They'll happily perpetuate the culture, just in a nicer and more up-to-date wrapping.
The renewal project comes along nicely. If they're any decent, they'll use the strangler method, which means that they won't try to do a complete rewrite at once, so for this story we'll give them the benefit of the doubt. For the next 4-5 years, they're replacing parts of the old system with the new one. The old system isn't completely replaced, but a lot of functionality has been moved over. Then we start seeing a negative trend in productivity for the team working on the renewal project...
Over the next decade, HealthWiseIT will fade into its legacy as new competition eats into its business. HealthWiseIT is lucky; they're in the business of healthcare, which has a history of being resistant to change. Since they specialise in niches, they might be able to cruise for a long time, but HealthWiseIT's growth will stagnate and eventually decline.
It would be near impossible for HealthWiseIT to change its internal culture, as the leaders who oversaw the initial success have grown into very influential positions within the company. They're unaware that their push for new features pressured developers to focus on deliveries over quality.
At the same time, the developers at HealthWiseIT have never really paid any technical debt. It isn't something that concerns them. They won't take responsibility for the state of the codebase. Most of the initial developers have left, and the remaining ones either agree with the company culture, blame management or haven't been around long enough to feel responsible.
Hiring new talent will be extremely difficult for HealthWiseIT. There's very little to be excited over. A difficult codebase, and days mostly spent putting out fires. Some talent might be brought in for the renewal project, but the most valuable of that talent will quickly leave as they start seeing the dysfunctional tendencies within the organisation.
Let's look at HealthWiseIT's decline and investigate the different aspects thmakekes the technical debt spirso deadly.
Technical excellence is difficult to measure for a non-technical manager and leader. In HealthWiseIT's story, the technical debt didn't manifest as problems for management years into the product lifecycle. In fact, hiring and turnover made it difficult for management to detect any issues as it polluted their performance metrics.
The delayed impact is a sinister effect of the tech-debt spiral, as it makes it easy to blame other aspects and allows a culture that will only perpetuate the issues to really manifest.
It doesn't help that the change is very gradual. There are no sudden changes, just a slow increase of errors and unnecessary complexity until the team slowly drowns. Once management finally catches on, they have also created a culture that defines success through new features and rapid development.
In fact, the change is so gradual and deceptive that at the end of HealthWiseIT's story, it is unlikely that they actually realise the core issue. Instead, they identify the superficial problems and try to tackle them but are utterly blind to the underlying issues.
The talent that you need the most when in the tech-debt spiral are the ones that will leave quickly. They might complain and push for improvements, but they will seek employment elsewhere if they're not heard.
HealthWiseIT were left with the managers and developers that didn't know any better and were happy to perpetuate the practices that only put them further down the spiral. Their benchmark for success was delivering new features, and during the first years, that is what the market responded to. The short term focus rewarded the managers, which again benefitted the developers.
The result was that HealthWiseIT were left with people more likely to resist change, and they alienated any new hires that could bring the change they needed.
As previously mentioned, HealthWiseIT's leadership were rewarded when pushing for new changes. During the company's early years, that is what the market responded to and the foundation the company was built around.
For management, it was difficult to connect the dots between the slowness of development to their focus on new functionality. After all, they don't write code. Instead, they expect developers to be responsible and write software that can be maintained. After all, that is why they hired developers - to be responsible for the software side of things.
When things started to slow down, it could be excused. Productivity was down, but not in a way that set off alarm bells. The developers complained about the state of the codebase, but HealthWiseIT had important deadlines to meet. Improvements could wait.
Later the cost of fixing issues exploded. We're no longer discussing a missed deadline or two but slicing the productivity in half for months. HealthWiseIT still had deadlines and new customers coming in, which took precedence. Management would love to make developers more effective, but there was no time for such a massive undertaking.
Thus, it continued for HealthWiseIT's leadership. They wanted to keep the momentum without paying the debt. Instead, they wanted short-term growth and ignored the long-term consequences. Such a culture pressures developers and encourages (and rewards) those willing to ignore quality for the sake of delivering.
As HealthWiseIT aged, new competitors started to show up. They didn't have the same burden in the form of technical debt as HealthWiseIT had. The competitors were leaner and could manoeuvre much faster, which made it difficult for HealthWiseIT to keep up.
However, HealthWiseIT leadership still saw it as a lean and young machine and put pressure on new functionality. Much like the previous point, this encouraged the leadership and developer culture that only worsened the technical debt.
At some level, HealthWiseIT were forced to focus on new functionality. New healthcare devices hit the market constantly, new integrations are needed, and many of their customers expect rapid support. If support doesn't come within a reasonable time, then a certain percentage will leave for competitors with the functionality they need.
The expectation of new functionality puts HealthWiseIT in a difficult position. They could invest in a costly rewrite or reduce the output, leading to lower adoption. HealthWiseIT can also push for new functionality at the cost of its own product's longevity.
HealthWiseIT had a decent income. They were doing pretty well, but their growth eventually stagnated, and so did their ability to force changes by getting more developers and doing more rewrites.
HealthWiseIT can't hire the talent needed to make a difference, nor do they have that talent internally. Nor can they throw money at new developers to outpace the problem.
At this stage, HealthWiseIT has no options other than seeing its productivity crash. Their customer base will dwindle as new changes barely come out, and when they do, they're riddled with bugs.

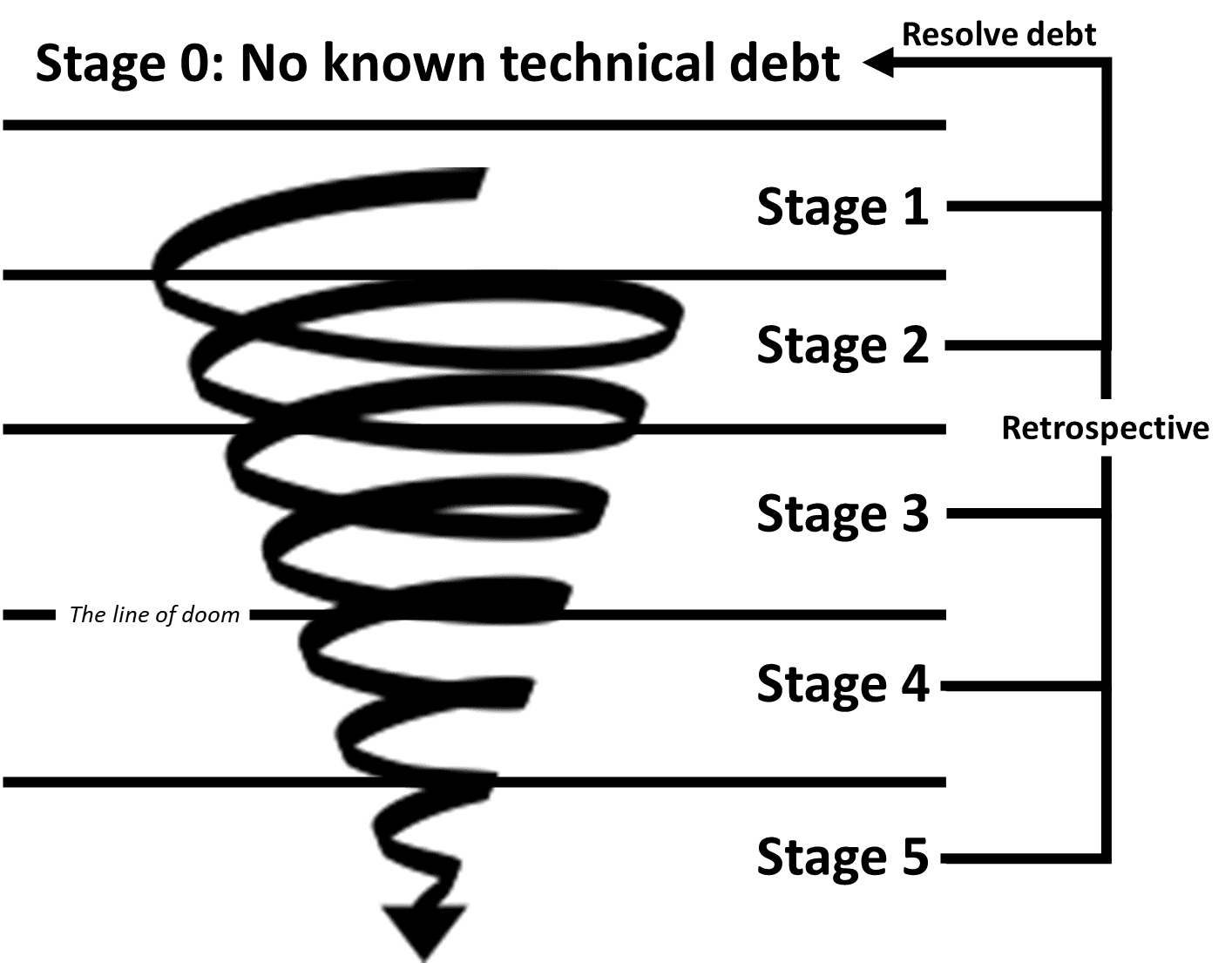
The impact and cost of fixing technical debt go hand-in-hand; therefore, we have the five stages of technical debt. As a result, the debt becomes more difficult to work with at each level, and the effort required to fix it increases.
Stage 1 is where most forms of technical debt are birthed. They often start out as small imperfections. shortcuts or something that the developers haven't considered:
At this stage, these things are not really an issue yet. They're a quick solution to solve a concrete problem. The developers might be aware that it isn't the best solution, but they'll do it anyway in the name of getting something done.
This is the stage where the fabled "TODO: FIX LATER" comments are written.
At stage 1, a lot of technical debts are not even viewed as technical debt. The developers might not have considered that they need a strategy for keeping their dependencies up to date. It might be their first shot at microservices, so they might not be aware of the implications of solely relying on synchronous HTTP calls.
Stage 2 is where the team will discover the technical debt. The debt itself is relatively easy to fix if one decides to invest the time, but it is also relatively easy to ignore it or work around it.
What often happens is that a developer runs into technical debt as they work on something else. Doing so, they're faced with a few options:
I often see developers choosing the latter.
Choosing to ignore technical debt and make a solution that compensates for it only makes it harder to remove it. Most workarounds also tie into the debt in some way, or they become technical debt themselves, which only adds to the problem.
At stage 2, technical debt is often described as "We know it is imperfect, and we're going to fix it at some point".
At stage 3, the technical debt has grown so much that it is difficult for the team to justify fixing it without formally slotting the fix in the middle of deliveries and projects. Doing so most likely means taking a noticeable hit to productivity within a sprint. The options are to deliver N new features to the stakeholders or fix this issue.
Fixing stage 3 technical debt can be a difficult decision for a team currently facing deadlines, some of which may very well be strict. At this stage, I often see teams take the "we'll fix it after this project" approach. But, in reality, we all know this is a lie because there's always the next project - and the debt is even harder to fix by that point.
Stage 3 is a critical point for fixing most tech debt. Fixing the debt is still manageable, and the team can decide to do so. This is the last stage the team can decide to do something with the debt without involving others in the decision-making.
Things start becoming really nasty after stage 3. Fixing debt will become so costly that its impact can be noticed by accounting.
Crossing this line means a few things, but I want to highlight the following two:
At stage 4, we're dealing with project-sized issues. Paying the debt will require weeks, if not months, of investment to resolve.
The upside is that paying the debt might not consume the entire team. They'll still be able to deliver, but the cost in terms of hours needing to be invested is not to be ignored. Fixing these kinds of debts will impact ongoing projects, and if the team has any timelines, it will put that at risk.
I try to avoid deadlines whenever possible, and I align myself with #NoEstimate, but that isn't how a lot of companies operate. It is interesting to see how deadlines play with stage 4 debt. The team and their manager often argue that they want to solve the problem, but not right now. Tackling the problem right now would pose a severe risk to the current delivery, which is very important (or so they say).
The decision is often concluded with a statement about being pragmatic.
The team and manager have forgotten (or ignored) that there's a deadline after the next deadline. So it turns out there's always a "next deadline", and for some strange reason, every single one of them is more important than the one that came before.
At the last stage, the team has pretty much given up. The old codebase can't be saved, and it is easier to rewrite the whole thing. The estimate for doing so might range from months to years and require a dedicated team to execute.
Stage 5, the rewrite stage., also reveals why rewrite projects often turn out to just restart the cycle: Nobody has learned anything throughout the process.
The developers have had stages 1 through 3 to take action. Management with developers had stage 4, and they decided not to. At every stage, decisions were made to ignore paying technical debt, which says something about the team's culture and management.
Getting to stage 5 can take years. For the people involved, it might be one of those things they've actively known about but feel they couldn't solve it. In other words, they've not taken responsibility actually to solve the problem.
Whom will the company pick to rewrite it? The best and brightest of those that did nothing to tackle the technical debt during steps 1, 2, 3 and 4...
I'll be honest: Most organisations cannot.
The core issue is human, and the people that allowed the spiral to happen in the first place have been rewarded with key positions within the org. They are the ones with the most influence and decision power. Culturally, the company rewards the behaviour that will also undo them.
A complete cultural reform is the only true way to break out of the spiral. I'm not implying that people should be fired, but it is clear that the people in leadership positions allowed it to happen. The developers allowed it to happen. Key positions need to be filled with people who value quality. Teams need to have a majority of people who want a healthy codebase and are willing to push back in the name of quality.
Such a change almost always fails, and we don't need to look further than "Larman's Laws of Organizational Behavior" to see why:
Organizations are implicitly optimized to avoid changing the status quo middle- and first-level manager and “specialist” positions & power structures.
As a corollary to (1), any change initiative will be reduced to redefining or overloading the new terminology to mean basically the same as status quo.
As a corollary to (1), any change initiative will be derided as “purist”, “theoretical”, “revolutionary”, "religion", and “needing pragmatic customization for local concerns” — which deflects from addressing weaknesses and manager/specialist status quo.
As a corollary to (1), if after changing the change some managers and single-specialists are still displaced, they become “coaches/trainers” for the change, frequently reinforcing (2) and (3), and creating the false impression ‘the change has been done’, deluding senior management and future change attempts, after which they become industry consultants.
(in large established orgs) Culture follows structure. And in tiny young orgs, structure follows culture.
In other words: Companies are set up to resist any meaningful change to its culture or structure.
HealthWiseIT created its culture based on delivering functionality during its first year; the next few solidified that culture. Therefore, changing that culture 8+ years in is nearly impossible.
There are things companies can do to extend the longevity of their solution:
The points above might put a company far down the tech-debt cycle into a more stable position, but it'll soon find itself back down again unless it adopts a culture that values paying technical debt.
This post has been very doom and gloom so far, but there is an answer to what one can do regarding technical debt - and it is surprisingly simple: Continuously remove cruft!
We can't avoid technical debt. Things outside our control might inflict technical debt upon us. We might not know that we're taking on some technical debt when implementing something. Avoiding all technical debt is not realistic. What is realistic, however, is making paying that debt part of daily work rather than ignoring it.
A culture that values paying the technical debt will solve most debts when they're still cheap in stages 1 and 2. For example, some might get to stage 3, but primarily due to developers unaware that it is a technical debt.
The list of things needed to maintain technical debt is surprisingly approachable:
All of the points above have one thing in common: They require the team and management to care about paying technical debt and improving the codebase and never knowingly allow technical debt to get to the next stage.
Having a team and company that values paying techncial debt doesn't guarantee that late-stage technical debt won't ever happen. Having such a culture will reduce the odds of it happening, but there are instances where technical debt is forced to stage 4 or 5.
An example of this could be that a core framework or library that the codebase depends on being deprecated. Maybe the team hasn't followed up on the news coming out from this framework, or the maintainers have poorly communicated it. Depending on the usage, this might force the technical debt straight into stage 4 or 5.
Maybe a newly discovered security vulnerability has roots deep within the codebase, and fixing it might require a lot of work. However, since the team did not know about the issue, they've not been in a position to resolve it, and as such, it has been allowed to spread.
Teams that allow technical debt to exist have stage 4 or 5 debt due to negligence, while teams that care only get to stages 4 and 5 due to external reasons.
I'd argue that for most people, there's no future within a company that is tumbling down the tech-debt spiral. Such a company might provide some opportunities for advancements in terms of titles, but the overall experience will only decline. There might be periods of optimism and excitement when doing the rewrites, but that is not sustainable in the long run.
The first question you have to ask yourself is how much influence you have over the current culture and how much needs to be done to get the team/company back on course. It will be near impossible for most developers, as top-down support is necessary, and even then, the majority of a team is often allowed to dictate its culture.
If you can't impact the culture in any meaningful way, or you're not willing to spend the years required to make that cultural shift (which is required), then I'd say you're better off finding employment elsewhere. There's no future in a spiralling company. Sure, the company may go on for many more years, but it will gradually decline in skill and enjoyment with moments of joy as rewrite projects happen. I rarely recommend people quitting, but if you're the kind of person that wants to grow as a professional and wants to learn from the best, then these companies are not the place for you. If you've gotten this far into this post, you most likely care a lot about what you do and won't enjoy being in a spiralling company.
For those who have influence and want to break out of the spiral, be prepared for an uphill battle. I tend to say that software would be easy if it were not for people, and that is also true here. Saying that we should be continuously paying technical debt is easy. Getting people to do it as part of daily work is an entirely different one. Saying that, we should assume that some time will be spent on paying debt sounds good on paper, but actually prioritising that when looking down the barrels of a tight deadline is much harder.
The problem with this culture shift is that you can't "sort-of" do it. You have to have a culture that values paying technical debt, or else it'll fall through. It doesn't help to have management that values it with a team that doesn't, nor does it work the other way around. It doesn't really help to have half a team that takes responsibility while the other half doesn't. Getting everyone on the same board is a monumental task.
This post started much shorter: Exploring the situation where a codebase and company cannot be salvaged. One point led to another, and now we're 5000 words in (give or take). Brevity has never been my strong suit, but if you got this far, I dearly hope you got something out of it.
If there are any conclusions to this post, it is that technical debt is often a quiet killer - at least it is initially. A thousand cuts can murder a codebase. Enough minor cruft instances become a considerable problem overall and rarely happen overnight. Developers often feel the impact of technical debt before they realise what they're dealing with.
The delayed impact of technical debt makes it even harder for nontechnical management. They can't really connect the dots between shortcuts taken and the impact of that shortcuts. The result is that management is often caught off guard when a "cleanup project" is all of suddenly required.

